May 25, 2024
接上一篇 ControlNet 算法原理与代码解释,本文主要整理一些类似的算法,即针对 Diffusion 的条件控制:
1. Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
- Project:https://pnp-diffusion.github.io/
- Paper:https://arxiv.org/abs/2211.12572
- Code:https://github.com/MichalGeyer/plug-and-play
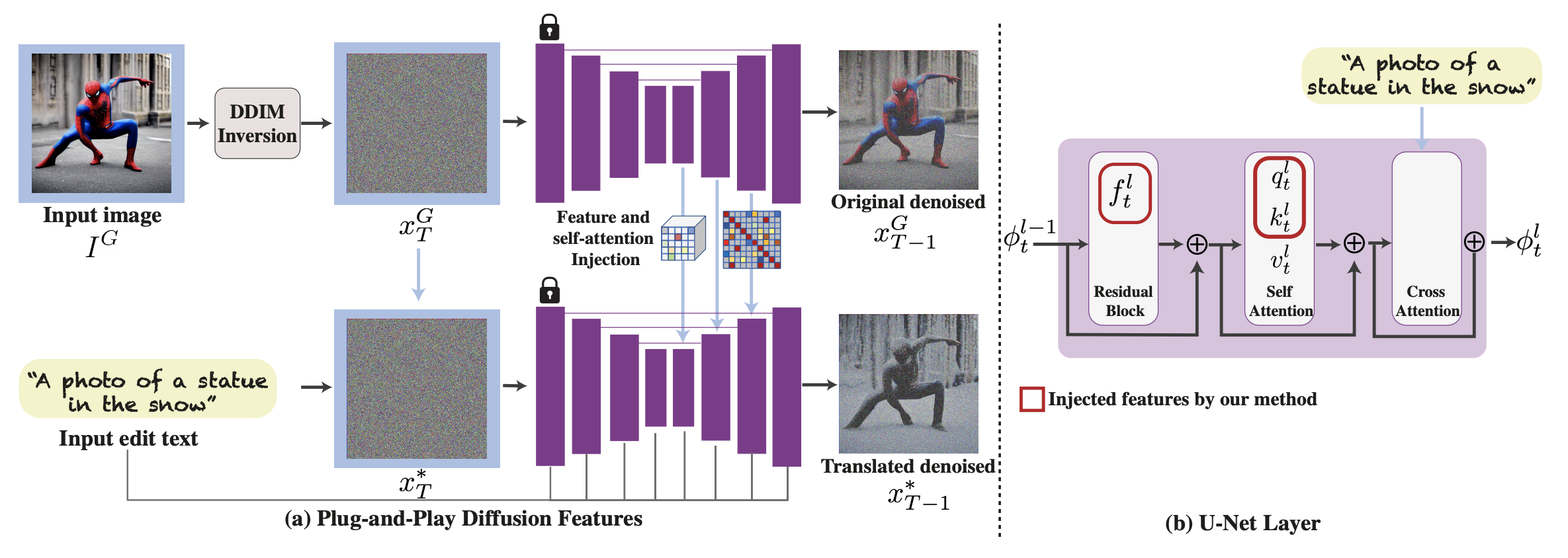
文本驱动的 img2img 生成,其条件控制是输入图的空间结构,文章主要基于对 UNet 各层 feature map 的分析:
- 粗粒度的 decoder 层特征主要由图像的的语义结构决定
- self-attention map 与图像的空间布局对齐(相似的区域对应相同的颜色)

因此文章提出的方案是:首先对输入图进行 DDIM Inversion,提取 spatial (ResNet) feature 和 self-attention maps,然后替换到结果图的 denoising 生成过程,整个方案无需训练,可以看作是对输入图 UNet feature 的“即插即用”
2. Sketch-Guided Text-to-Image Diffusion Models
线稿图引导的 text2img 生成,方案整体分为两步:
-
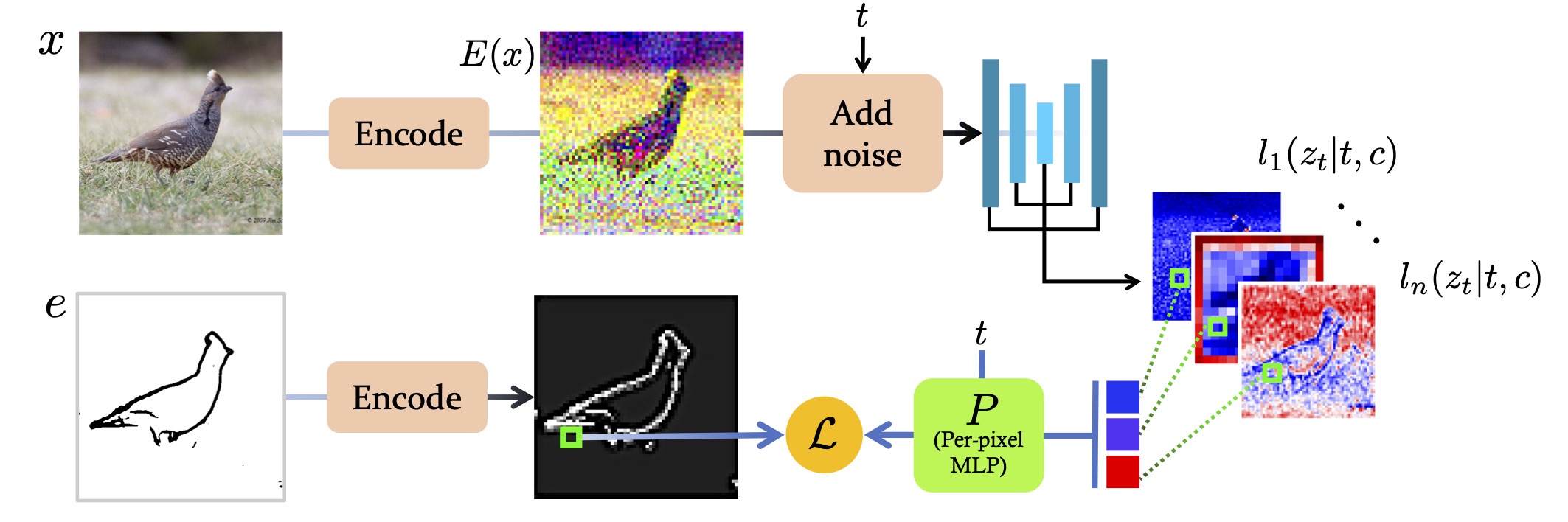
Latent Edge Predictor 训练
先训练一个 MLP 小模型,其作用是根据 UNet 中间步骤的 spatial features 预测其对应的边缘线条,训练过程如下:
-
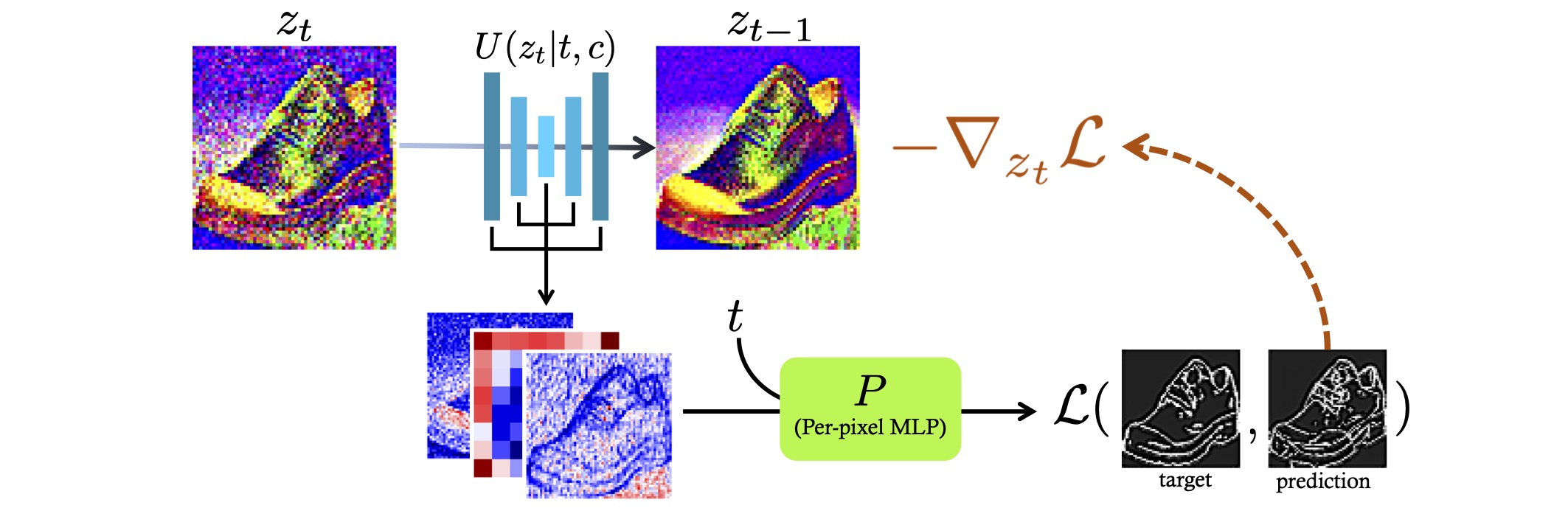
text2img 生成
这一步则是在常规的 denoising 过程中,用前面训练好的 Predictor 推理得到当前 t 对应的线稿图,然后对比输入线稿图计算相似度,最后基于这个相似度的梯度来引导去噪过程,使得结果图的边缘越来越接近输入图
该方案的 Predictor 是一个简单的 MLP 结构,且没有和文本 Prompt 关联,所以边缘的语义信息并不一定能很好地保持,比如结果图和输入图的边缘在像素空间能对上,但语义层面却对不上,如下图所示的 badcase:

3. GLIGEN: Open-Set Grounded Text-to-Image Generation
- Project:https://gligen.github.io/
- Paper:https://arxiv.org/abs/2301.07093
- Code:https://github.com/gligen/GLIGEN
较为通用的一种 text2img 扩散模型条件控制方案,首先冻结原 UNet 的参数,然后在各层 Self-Attention 之后中新增了一层 Gated Self-Attention,用于接收额外的条件控制信息,模型的训练只训练新增层的参数,Gated Self-Attention 基于残差结构,系数 γ 初始为 0,使得模型的训练更稳定,估计这也是取名 Gated 的原因,看到这是不是想到了后来 ControlNet 的零卷积结构,有着异曲同工之妙
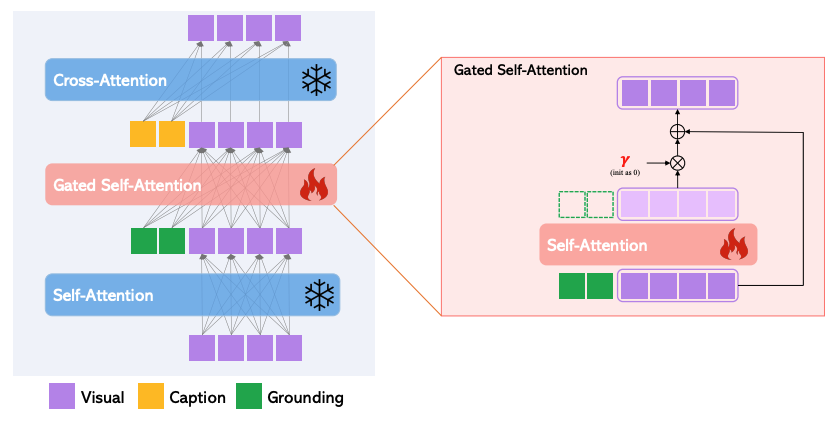
上图的条件控制输入(绿色方块),文章中称为 Grounding Tokens,支持多种类型的输入,先来看文本+位置框的情况,如下图,文本先经过 Text Encoder 得到 Text Embedding,再和位置框信息拼接,然后经过一个 MLP 网络得到融合表征 Grounding Tokens
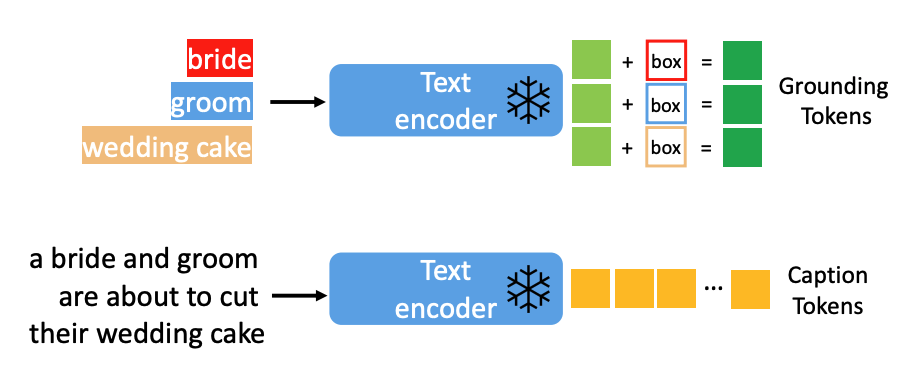
如果是图片+位置框,则 Text Encoder 改为 Image Encoder,如果是关键点,则和位置框一样进行处理(Fourier embedding),而如果是纯图条件(用于空间对齐),如边缘图、深度图、法线图等,则使用一个小的卷积网络来对条件图进行 encode 得到 Grounding Tokens,文章发现,如果将纯图条件输入到 UNet 的首个 Conv,能加速训练,此时 UNet 的输入就是 CONCAT(Conv(img), Zt),看到这是不是又想到了 ControlNet 对 condition 图的处理,也是通过几层 Conv 进行下采样, 再和 Zt 相加输入到 UNet
4. T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
与 ControlNet 几乎同时发表的 text2img 条件控制方案,整体架构如下图:
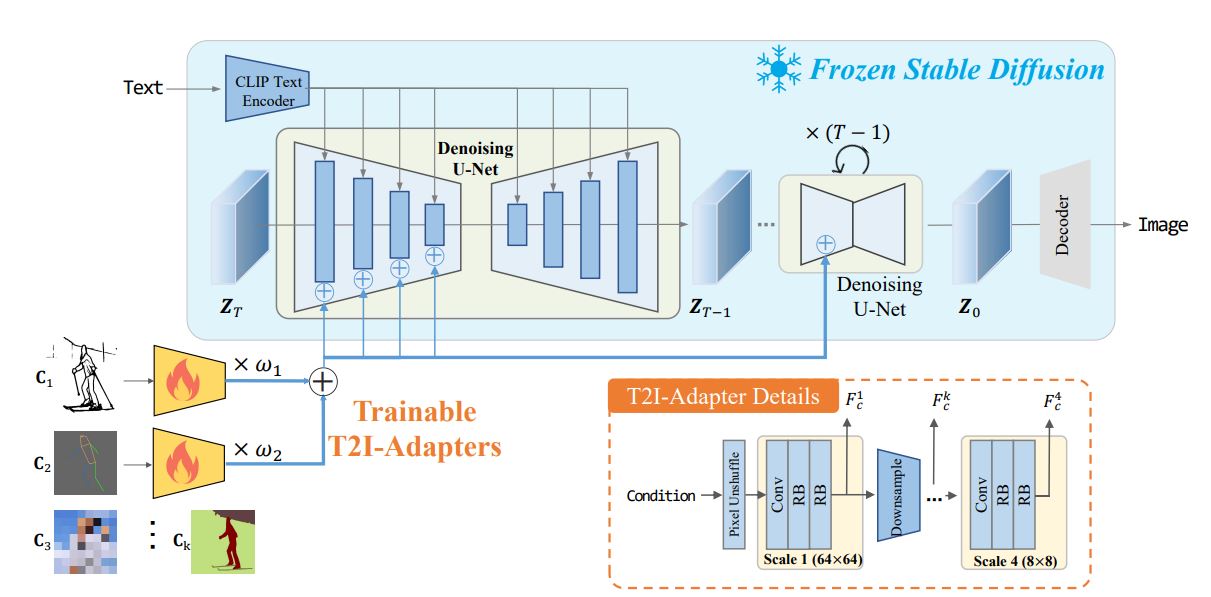
原 UNet 是完全冻结的,只训练一个个小的 Adapter,每种 Adapter 对应一类 condition,如线稿图、深度图、骨架图等,多个 Adapter 可以叠加使用,Adapter 本身由 pixel-unshuffle + Conv + residual blocks 构成,得到的 feature 再 Add 到原 UNet Encoder 各个 layer。
对比 ControlNet,T2I-Adapter 的优点在于模型更小,且在整个去噪过程中仅运行一次,显存占用和计算量都更小。不过如前面的文章 ControlNet 算法原理与代码解释 中提到的 ControlNet-Lite,T2I-Adapter 基本可以看作是一样的结构,其缺点在于对 Condition 语义信息的保持会有问题,这里就不再赘述。
5. UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild
- Project:https://canqin.tech/UniControl-Page/
- Paper:https://arxiv.org/abs/2305.11147
- Code:https://github.com/salesforce/UniControl
之前的 ControlNet 和 T2I-Adapter 对于每种类别的 Condition 都需要单独的模型来控制,这篇文章的方案则是用一个统一的模型来实现,只需训练一次,结构如下:
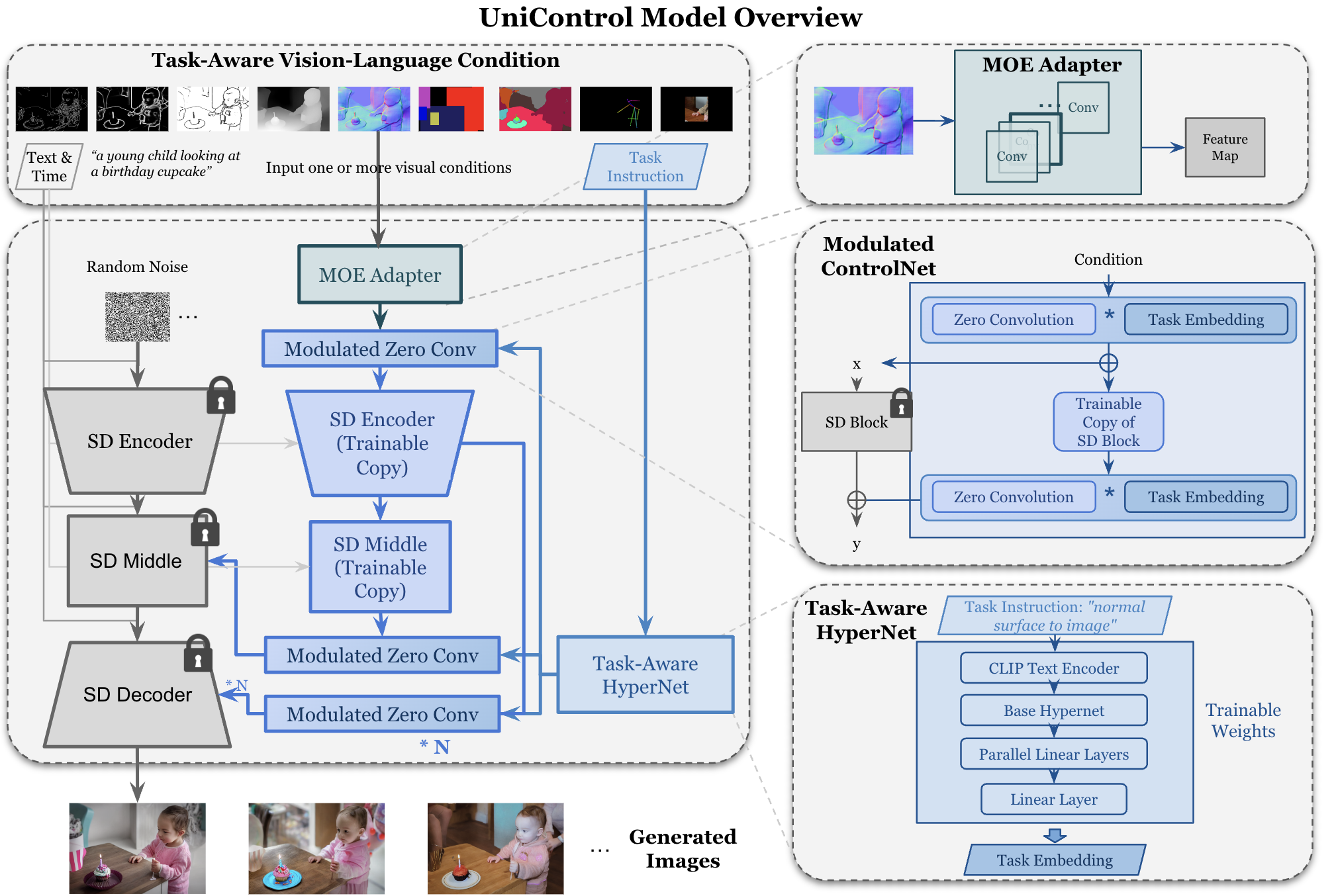
可以看到,其在 ControlNet 的基础上,新增了两个模块:
- MOE-Style Adapter:由一组 Conv 构成,基于 MOE 的思路,用于适配不同的 Condition 输入
- Task-Aware HyperNet:先使用 CLIP 对任务指令(新增的输入)进行 encode,然后经过几层 MLP 生成 Task Embedding,再作用到 ControlNet 的零卷积层(直接 element-wise 乘)
整体上可以看作是对 ControlNet 的输入输出进行额外的控制,从而实现多任务适配
6. Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models
- Project:https://shihaozhaozsh.github.io/unicontrolnet/
- Paper:https://arxiv.org/abs/2305.16322
- Code:https://github.com/ShihaoZhaoZSH/Uni-ControlNet
与上一篇一样,使用一个模型来支持不同类型的条件控制,文章把输入条件分为两大类:Local 和 Global,然后用两个 Adapter 分别进行处理,整体还是基于 ControlNet,如下图所示:
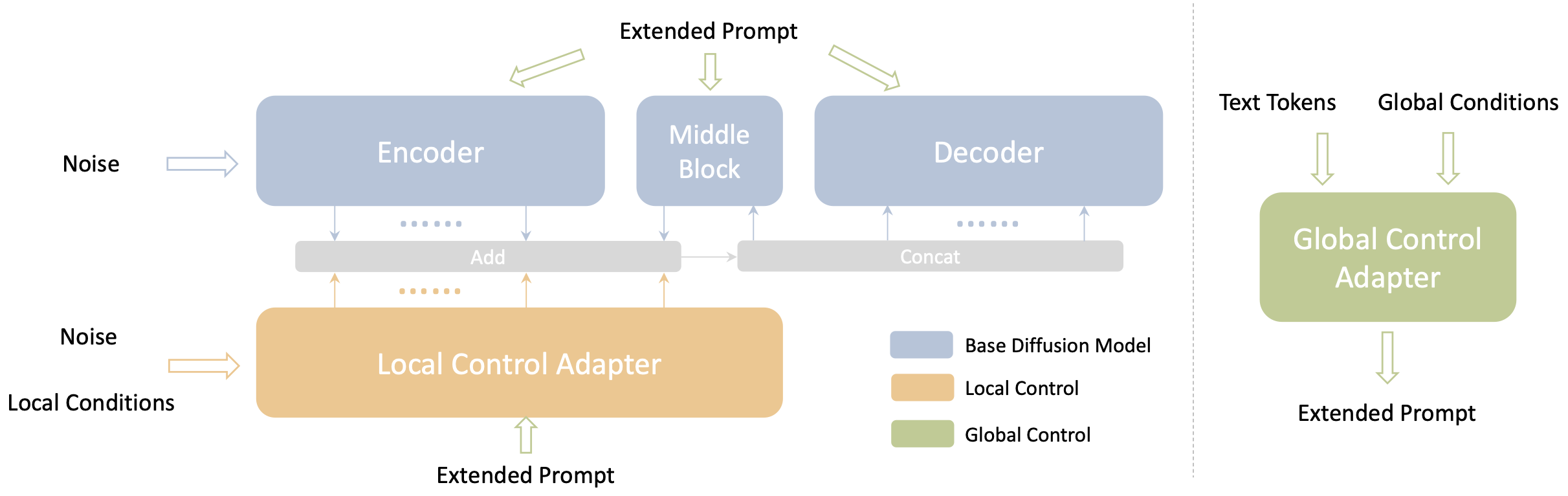
具体的两个 Adapter 的结构如下:
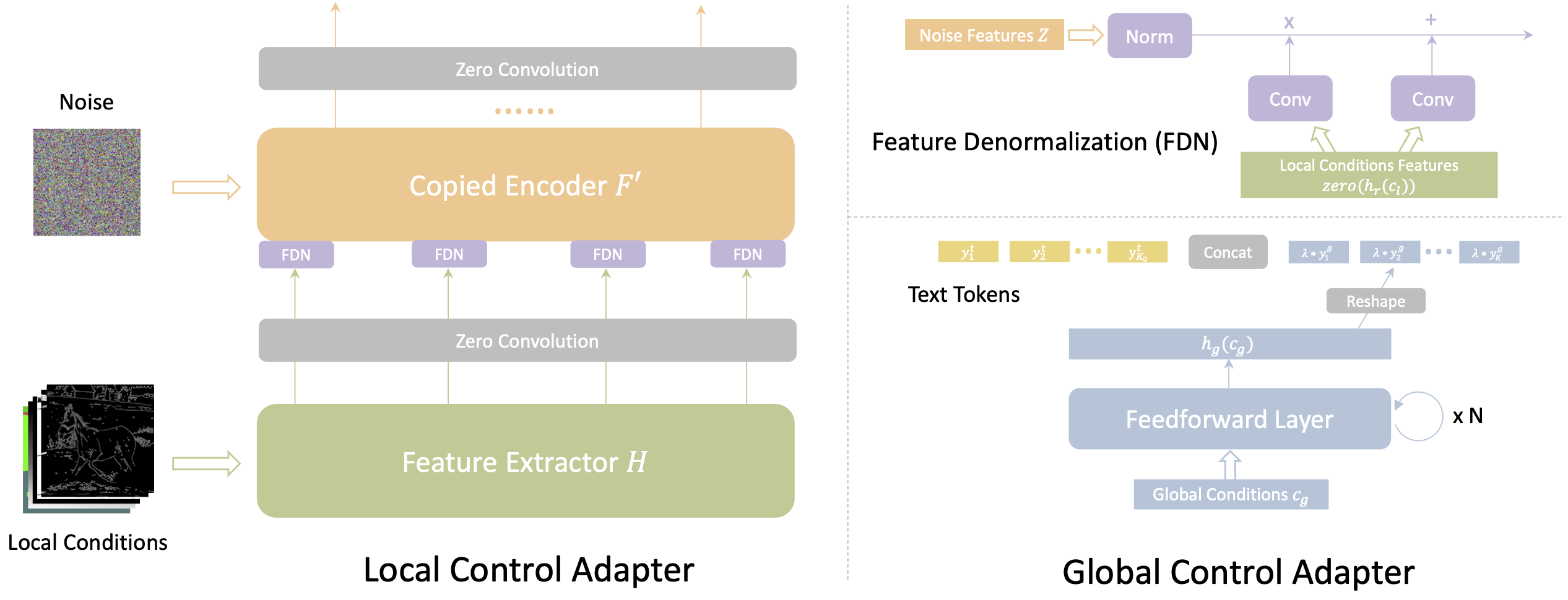
不同的 Local condition 按通道拼接在一起,然后经过 Conv 组成的 Feature Extractor,再经过零卷积和 FDN 作用到 ControlNet 的 Encoder 层输入(和Zt相乘),Global Condition (如图片)则先经过 CLIP Encoder 得到 embedding,再通过一个由 feedforward 层组成的 Condition Encoder 映射得到 global tokens,global tokens 再和 text tokens 拼接起来作为 UNet 的 cross-attention 输入。
7. FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
- Project:https://genforce.github.io/freecontrol/
- Paper:https://arxiv.org/abs/2312.07536
- Code:https://github.com/genforce/freecontrol
无需训练且支持多种输入的 text2img 条件控制方案,可以看作是在前文第一篇 Plug-and-Play 的基础上发展而来,Plug-and-Play 的方案直接把条件图 DDIM Inversion 的 feature 替换到结果图的生成过程,如果条件图不是自然图像则生成效果不好,比如深度图、骨架图等,这篇文章则新增了 Appearance Guidance,使得保持空间结构的同时,外观也不会受到太大影响,整体架构如下:
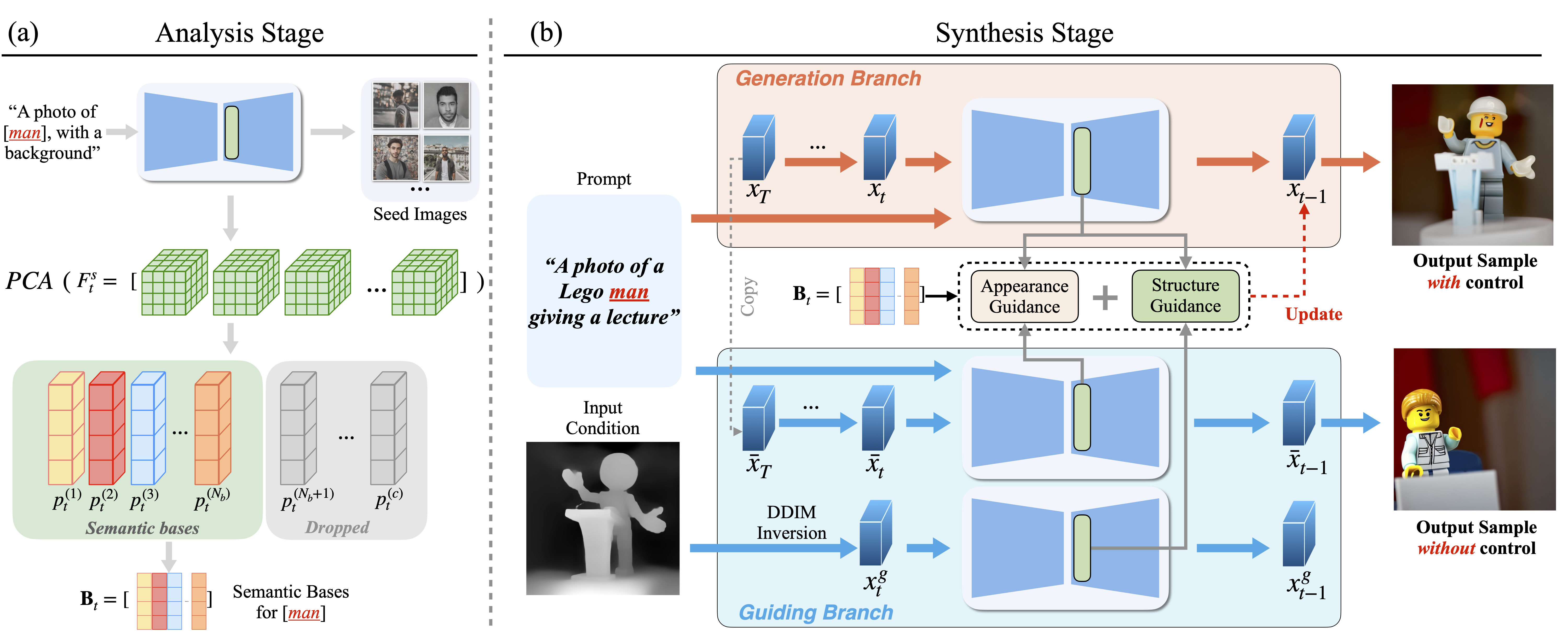
方案分为分析和生成两阶段,分析阶段先用 diffusion 根据目标概念生成一组图,同时对生成过程中 UNet 的 feature 进行 PCA 分析,得到一组语义表征的“基向量”,然后在生成阶段,将3个 UNet 的 feature 都投影到“基向量”空间,再根据相关性来引导结果图的 Denoising 过程(具体计算详见论文),实现外观+结构控制,3个 UNet 分别是:
- 对输入 Condition 图进行 DDIM Inversion 所用 UNet
- 根据输入 Prompt 和 copy 出来的 Xt 进行正常 Denoising 生成(无条件控制)所用 UNet
- 目标结果图 Denoising 生成所用 UNet(Generation Branch)
8. SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing
- Project:https://scedit.github.io/
- Paper:https://arxiv.org/abs/2312.11392
- Code:https://github.com/modelscope/scepter
通过对 UNet 中的 Skip Connection 进行修改来实现 text2img 微调和条件控制,如下图所示:
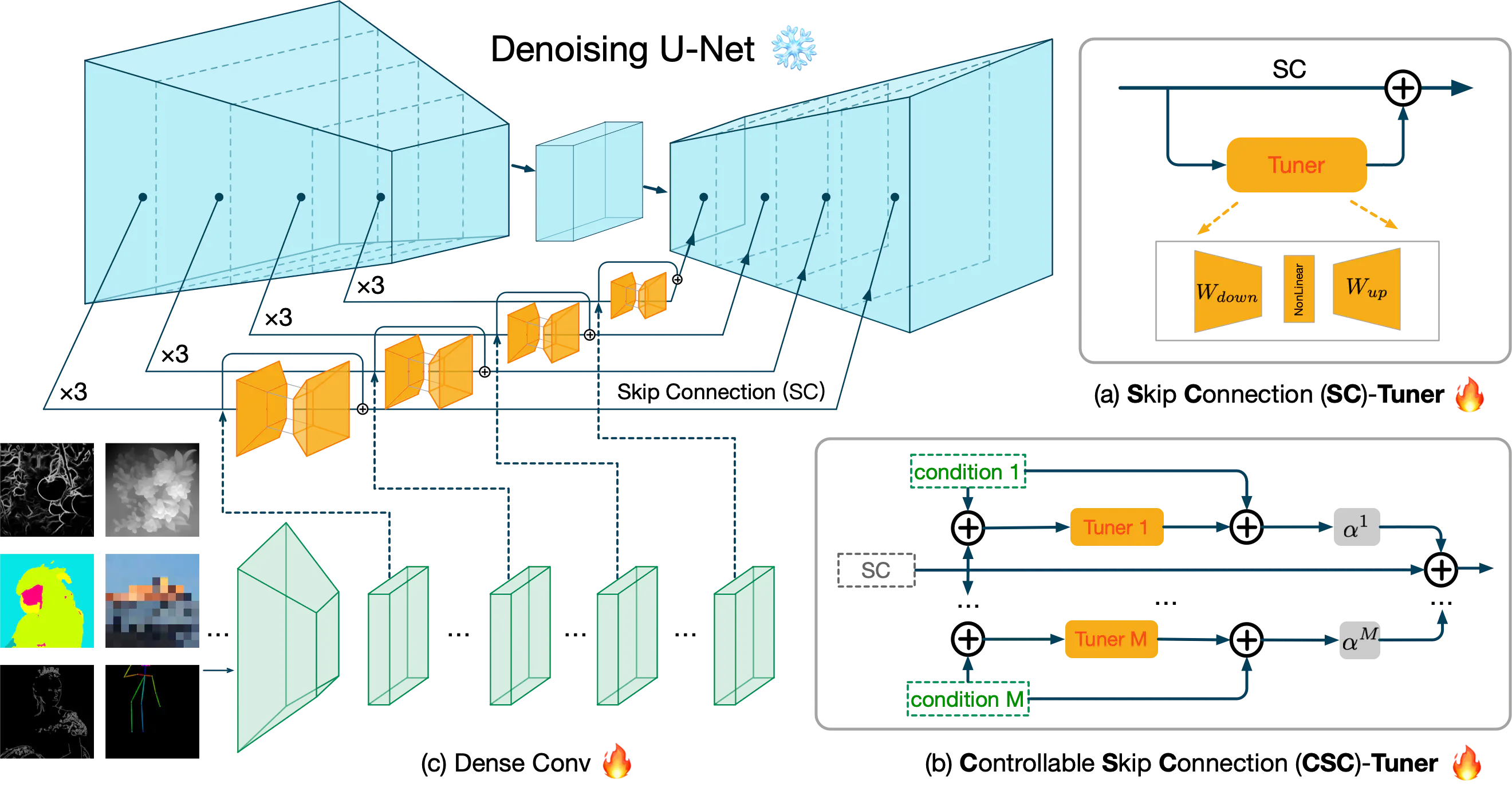
图中 (a) 是文章提出的 Tuner 结构,由上、下采样 Projection 和一个非线性激活构成,Tuner 再附加到 Skip Connection,形成一个类似残差的结构,如果只是微调 text2img 生成,则只需训练新增的 Tuner 即可,如果想进行条件控制,则如 (b)(c) 所示,把 condition 图先经过 Conv 处理,再 Add 到 Tuner 的输入输出,并且这里支持多种 condition 的同时作用,分别用不同的 α 来控制权重。
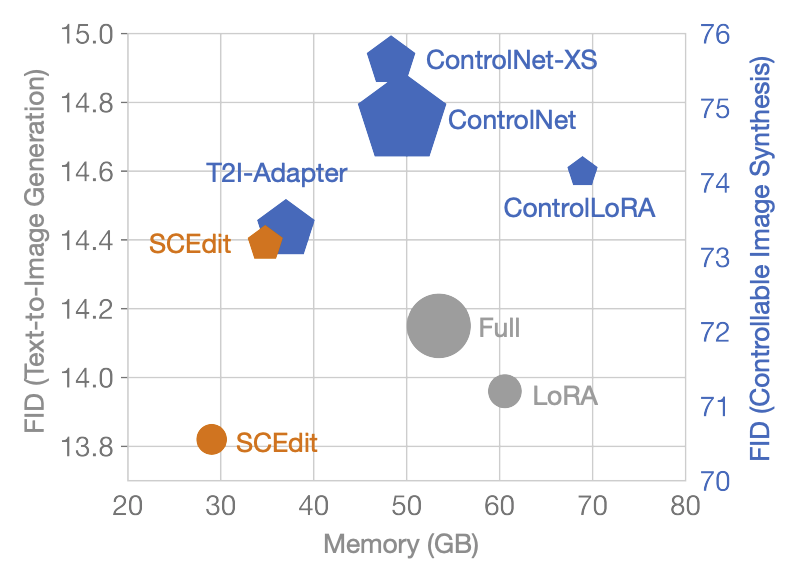
对比现有的方案如 ControlNet、T2I- Adapter 等,SCEdit 更加轻量高效:
9. ControlNet-XS: Designing an Efficient and Effective Architecture for Controlling Text-to-Image Diffusion Models
- Project:https://vislearn.github.io/ControlNet-XS/
- Paper:https://arxiv.org/abs/2312.06573
- Code:https://github.com/vislearn/ControlNet-XS
文章首先分析了 ControlNet 存在的延迟反馈问题,然后提出了改进方案,使得模型更小、更高效。所谓“延迟反馈”,指的是 ControlNet 复制出来的 Encoder 和 原 UNet 的 Encoder 是独立执行的,Control 的反馈直到 Decode 阶段才生效,并且因为两个 Encoder 独立执行,复制出来的 Encoder 需要具备同等的模型能力才能保证 correction/controlling 效果,Encoder 只能从原 UNet 复制,导致模型参数量很大,这里的问题其实 ControlNet 作者也有探讨,详见 ControlNet 算法原理与代码解释
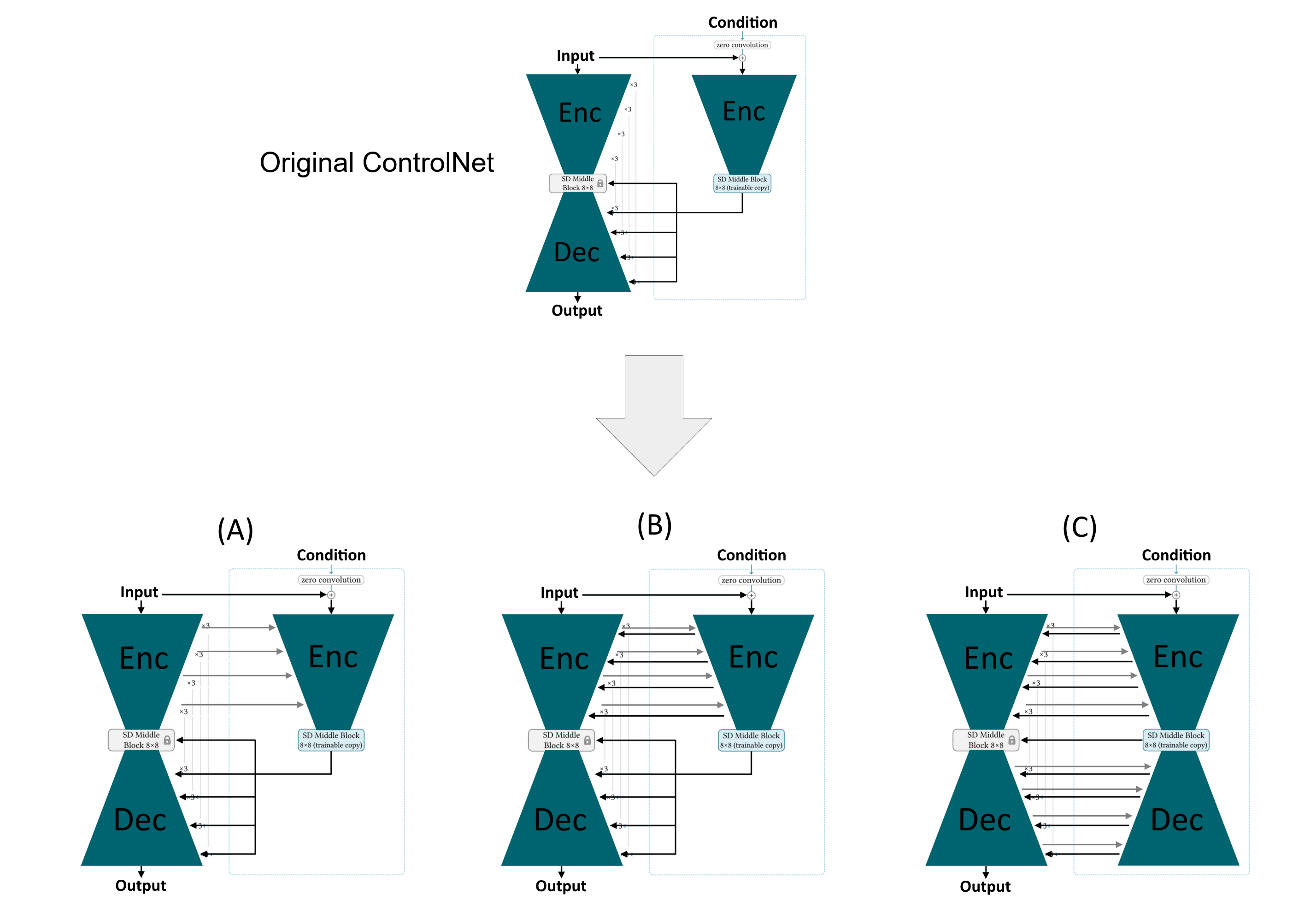
如上图是文章提出的解决方案,主要想法是提前把两个 Encoder 的各层连接起来,以解决延迟反馈问题,(A)、(B) 分别是单向连接和双向连接,(C) 则把 Decoder 部分也加进来测试效果会不会更好,这里的“连接”都加了零卷积来使训练更稳定。增加连接之后,Control 部分的 Encoder 就不再需要之前那么大,文章通过缩小各层通道数来降低参数量,并且做了多组对比实验,结果表明即使只有原模型 1% 的参数量也能得到很好的控制效果,FID 分数甚至更高。由于修改了 Encoder 结构,这里的需要需要从头开始。
此时对比 ControlNet-Lite,以及 T2I-Adapter,可以看到三者都有相似之处,猜测控制效果上和原 ControlNet 的区别主要还是对 condition 的语义结构的保持,需要在无 Prompt 的情况下测试。
10. ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
- Project:https://liming-ai.github.io/ControlNet_Plus_Plus/
- Paper:https://arxiv.org/abs/2404.07987
- Code:https://github.com/liming-ai/ControlNet_Plus_Plus
我们知道如 ControlNet、T2I-Adapter 等模型,训练的时候并没有修改 Loss 的计算,仍然是基于 UNet 预测噪声的差异,而这篇文章则在此基础上新增了一项 Loss,如下图所示:
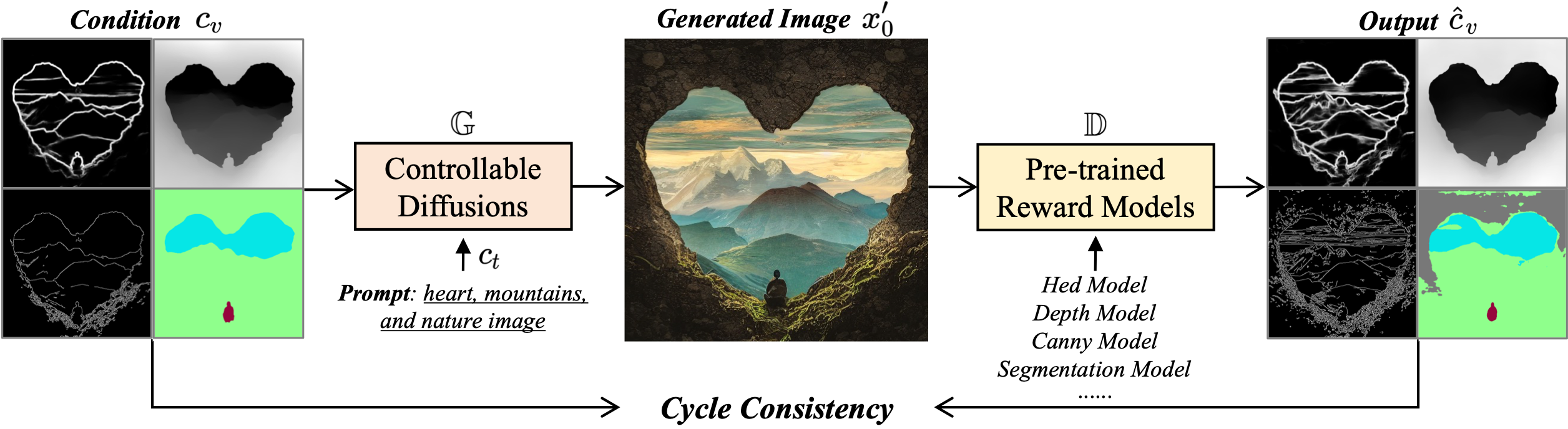
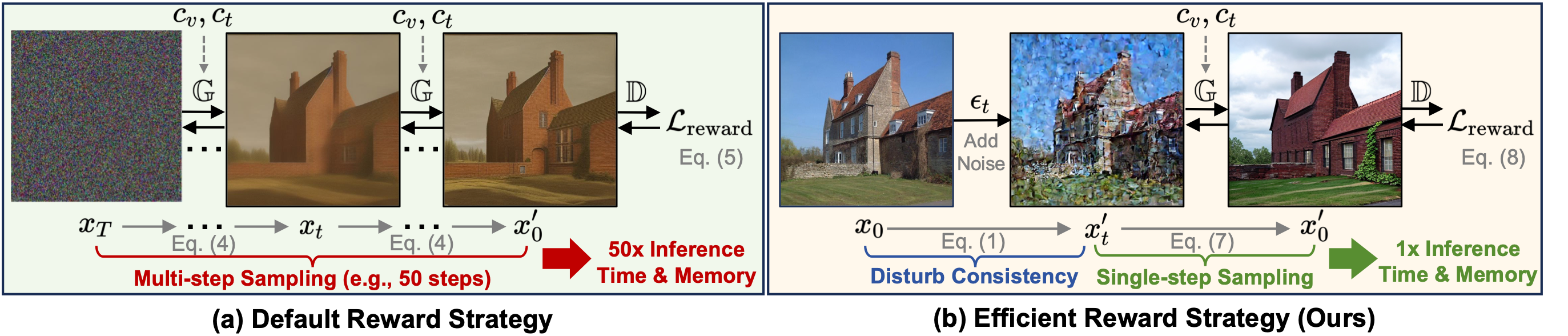
也就是输入 Condition 图生成结果图后,再使用一个预训练的模型从结果图提取新的 Condition 图,然后基于两个 Condition 图的差异(像素空间)作为 Loss 来优化生成模型。这种想法其实也挺自然的,但实践过程中会遇到计算量过大的问题,因为 Diffusion 的生成需要多步采样,要进行梯度下降得把每一步的梯度都存起来,这篇文章采用的优化方案是只在 t 很小的时候对训练图加噪,破坏与条件图之间的一致性,然后进行去噪生成,提取条件再得到 Loss
最终训练的 Loss 如下:
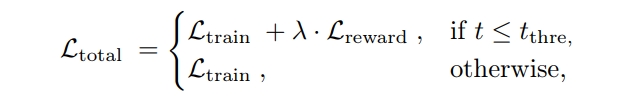
11. SmartControl: Enhancing ControlNet for Handling Rough Visual Conditions
- Project:https://smartcontrolnet.github.io/
- Paper:https://arxiv.org/abs/2404.06451
- Code:https://github.com/liuxiaoyu1104/SmartControl
文章在 ControlNet 的基础上,主要解决 Prompt 和 Condition 冲突的问题,在 Condition 的空间结构和 Prompt 没法一致的情况下,现有的 ControlNet 会倾向于保持空间结构,使得生成结果真实性降低,本文的方案则是在 ControlNet Decoder 输出作用到原 UNet 的时候,新增一个 Control Scale Predictor,用于动态调整 Control 强度,使得生成结构只保持粗粒度的空间结构,提高真实性。Predictor 本身由 Conv+ReLU 层构成,整体结构如下图所示:
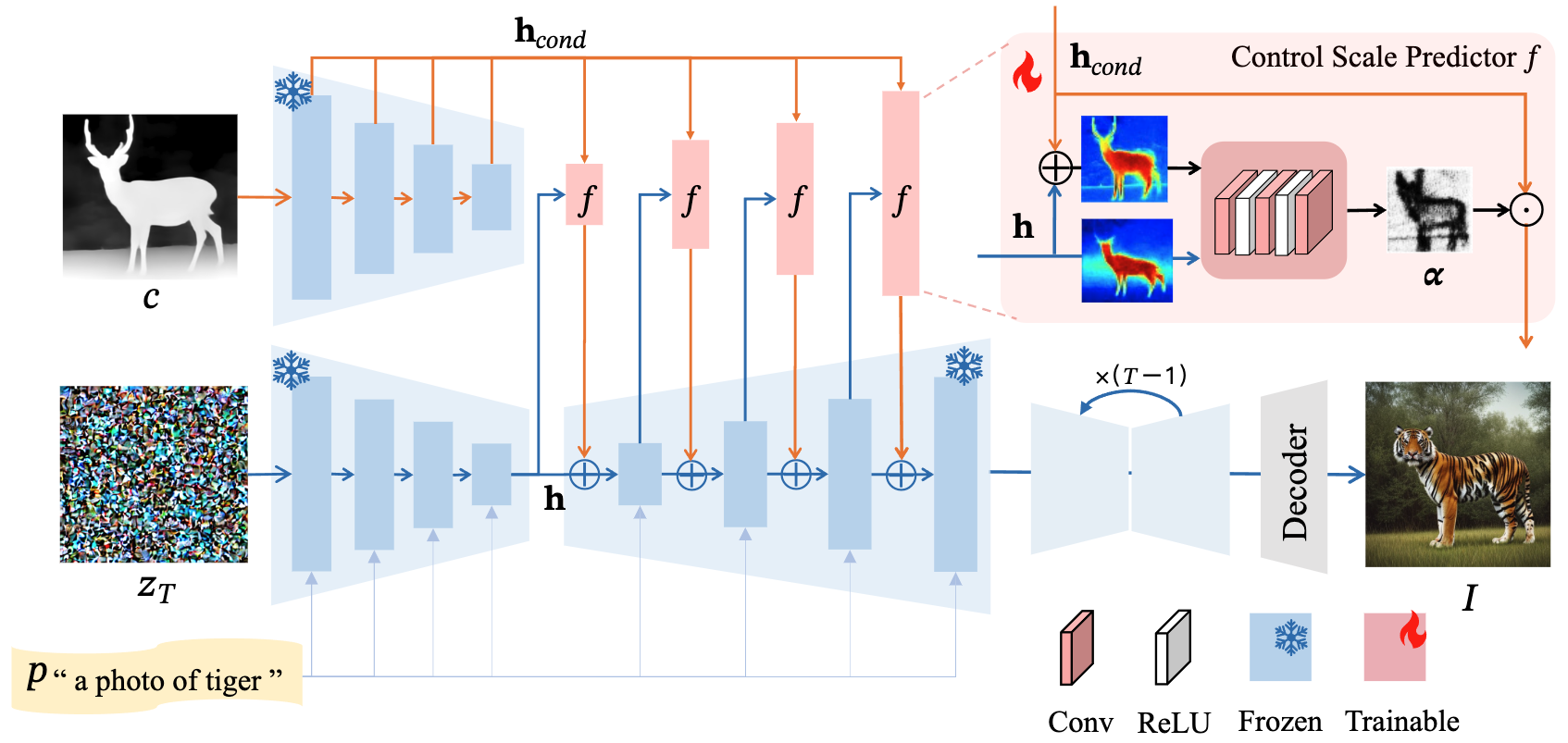
训练的时候冻结原 ControlNet 和 UNet 的参数,只训练新增的 Predictor 即可。
12. Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance
- Project:https://genforce.github.io/ctrl-x/
- Paper:https://arxiv.org/abs/2406.07540
- Code:https://github.com/genforce/ctrl-x
无需训练的 text2img 结构+外观控制,整体结构如下图:
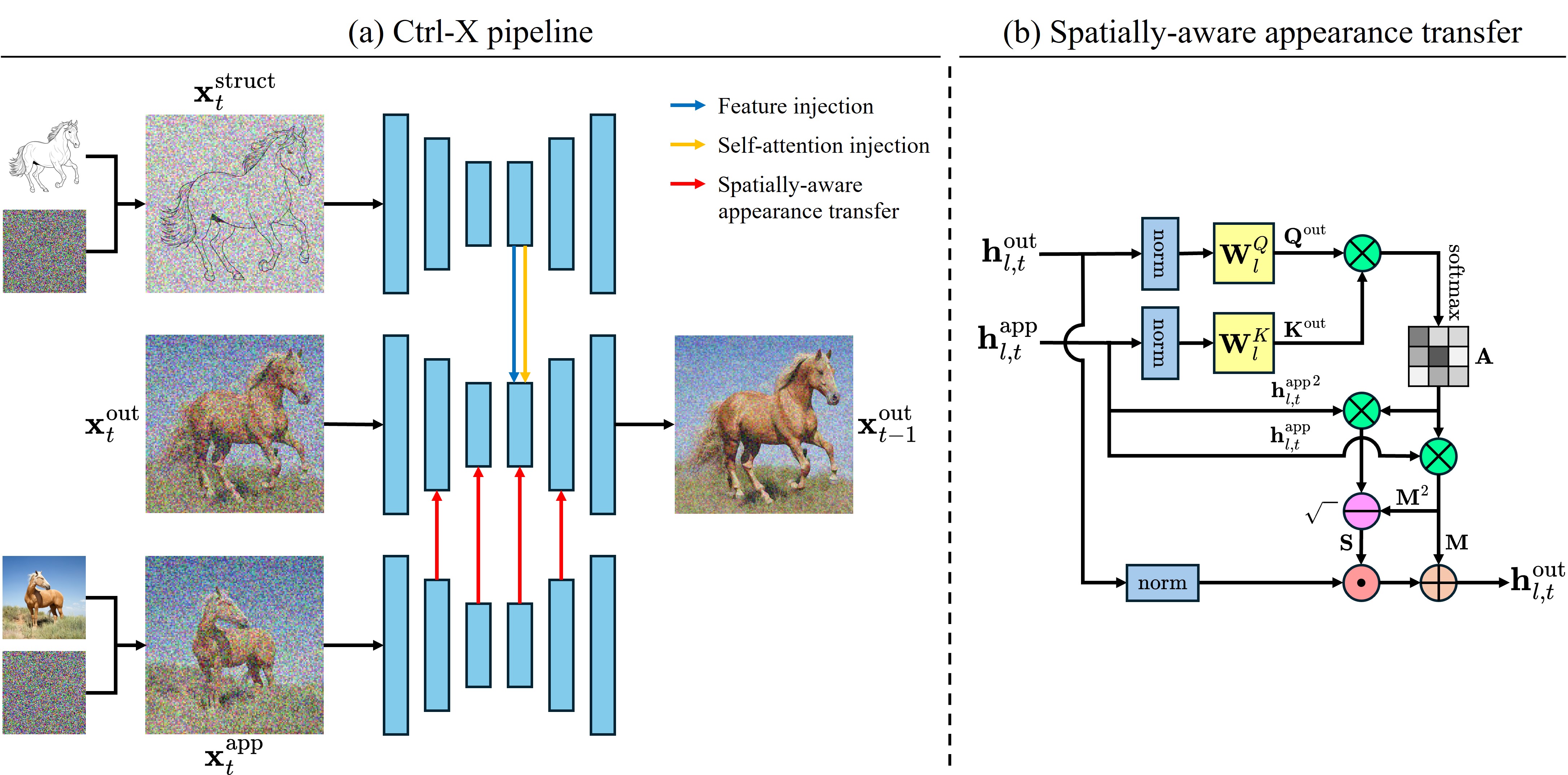
- 结构控制:和本文第一篇 Plug-and-Play 类似,将 UNet 各层 ResNet 和 Self-Attention feature 替换到目标 UNet,不过这里并没有使用 DDIM Inversion,而是直接在 Condition 图上加噪(forward diffusion),然后输入到 UNet,实验表明 decoder 层的 feature 也包含了足够的空间信息
- 外观控制:与结构控制类似,区别在于不是直接替换 feature,而是采用 AdaAttN 的方法来实现外观迁移,这里其实与 ReferenceNet 很像,只是两个UNet layer 间的“关联”改成了 AdaAttN