April 30, 2024
ControlNet 是 ICCV 2023 的一篇 paper,原文:Adding Conditional Control to Text-to-Image Diffusion Models,其目的是在 Diffusion 图像生成时增加条件控制,与通常的文本 Prompt 不同,ControlNet 支持在像素空间做精细控制,如下图的三个示例,分别是通过 Canny 边缘、人体姿态、深度来控制图像的生成,左上角是输入的 condition 图,其余是 Diffusion 生成的结果图,可以看到控制非常有效,并且图像质量没有明显下降,整体和谐:

算法简介
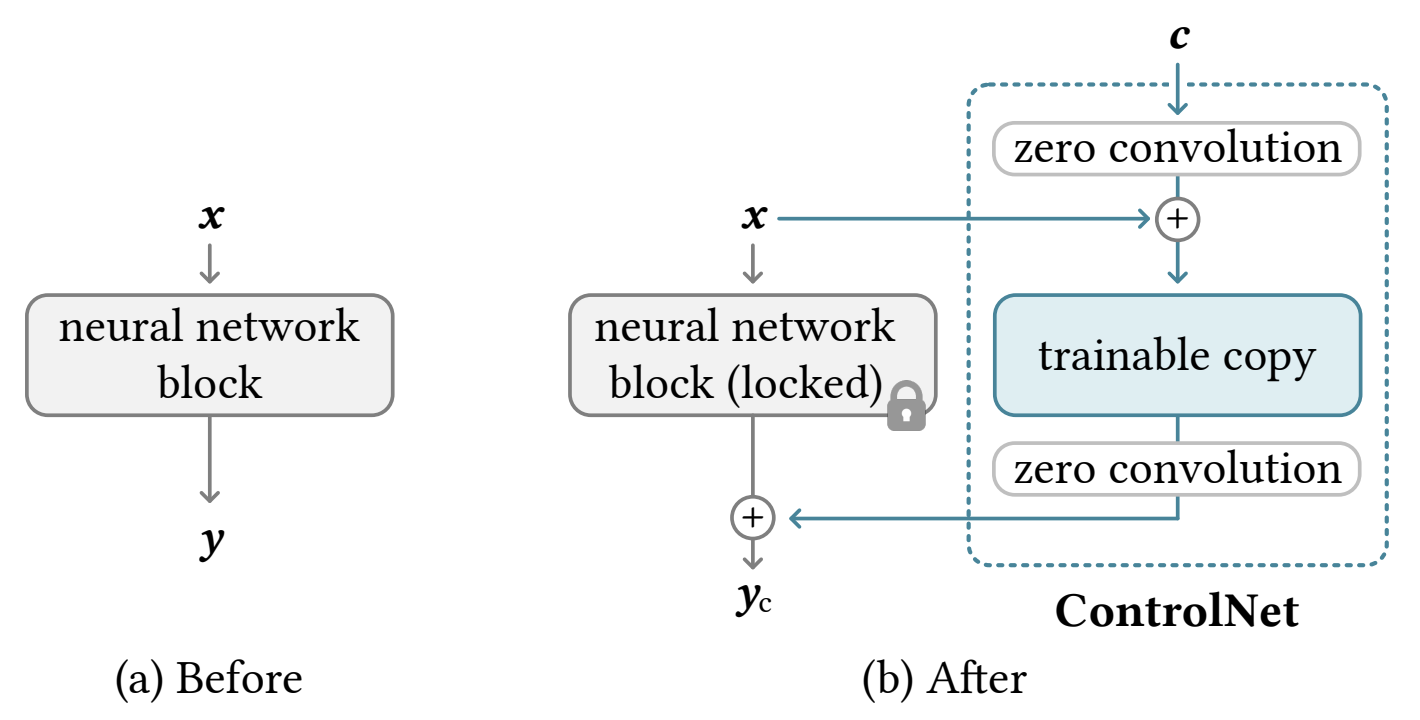
ControlNet 采用了一种类似微调的方法,如下图,在原模型的基础上,增加一个可训练副本,可训练副本的输入是原输入x加上条件c,然后把两个模型的输出相加,可训练副本的输入输出都经过零卷积(zero convolution)处理,用于在刚开始训练时保持模型的稳定性。
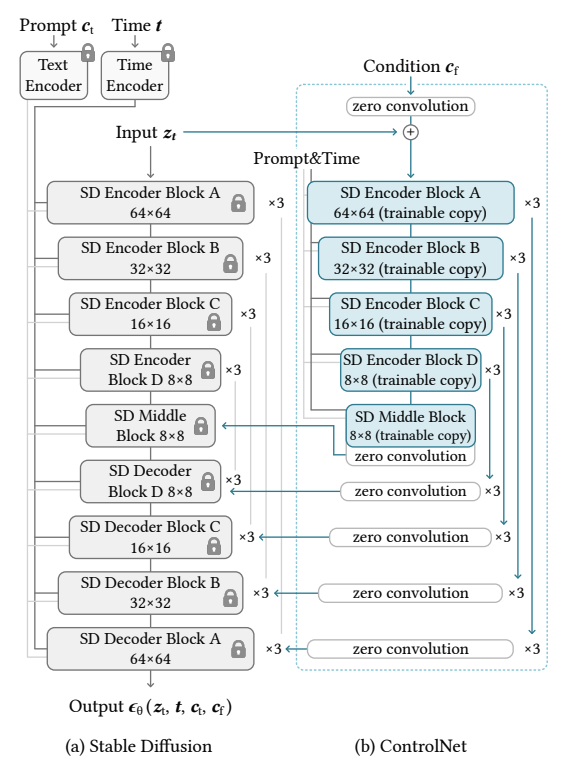
具体的针对 Stable Diffusion 的 ControlNet 结构如下图,只复制了 UNet 的 Encoder blocks 和 Middle block (结构+权重),控制条件图c先经过几层卷积,再与原UNet的输入zt相加作为输入,ControlNet 每个 block 的输出再 Add 到原 UNet 的 Decoder block 输入,实际实现中,ControlNet 的输出还可以乘上一个scale,用于控制影响程度。注意这里 ControlNet 同样输入了和原 UNet 一样的 Prompt&Time
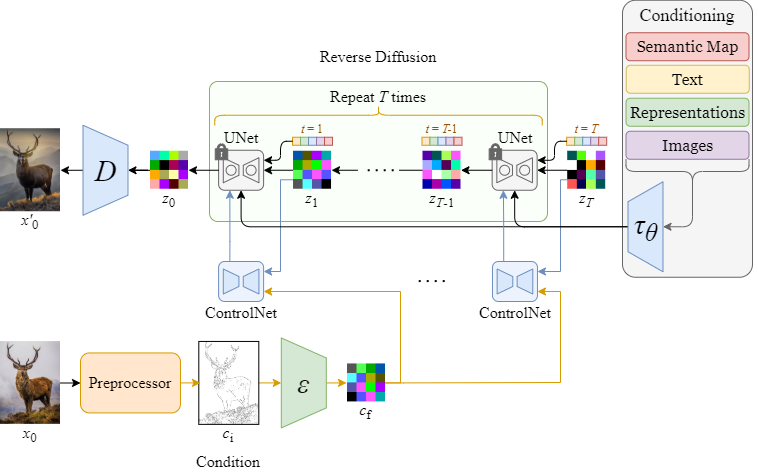
完整的 Diffusion + ControlNet 流程如下:
优化探索
除了上文 Paper 中的结构,ControlNet 的作者还探索了一些优化方案,主要围绕更轻量的模型,更快的推理速度来做:
1. ControlNet-Lite/MLP
Paper 中的 ControlNet 复制了 SD UNet 的整个 Encoder 部分,显存占用和推理速度都有较大影响,那能不能用更轻量的结构呢?作者尝试了两种简化结构:
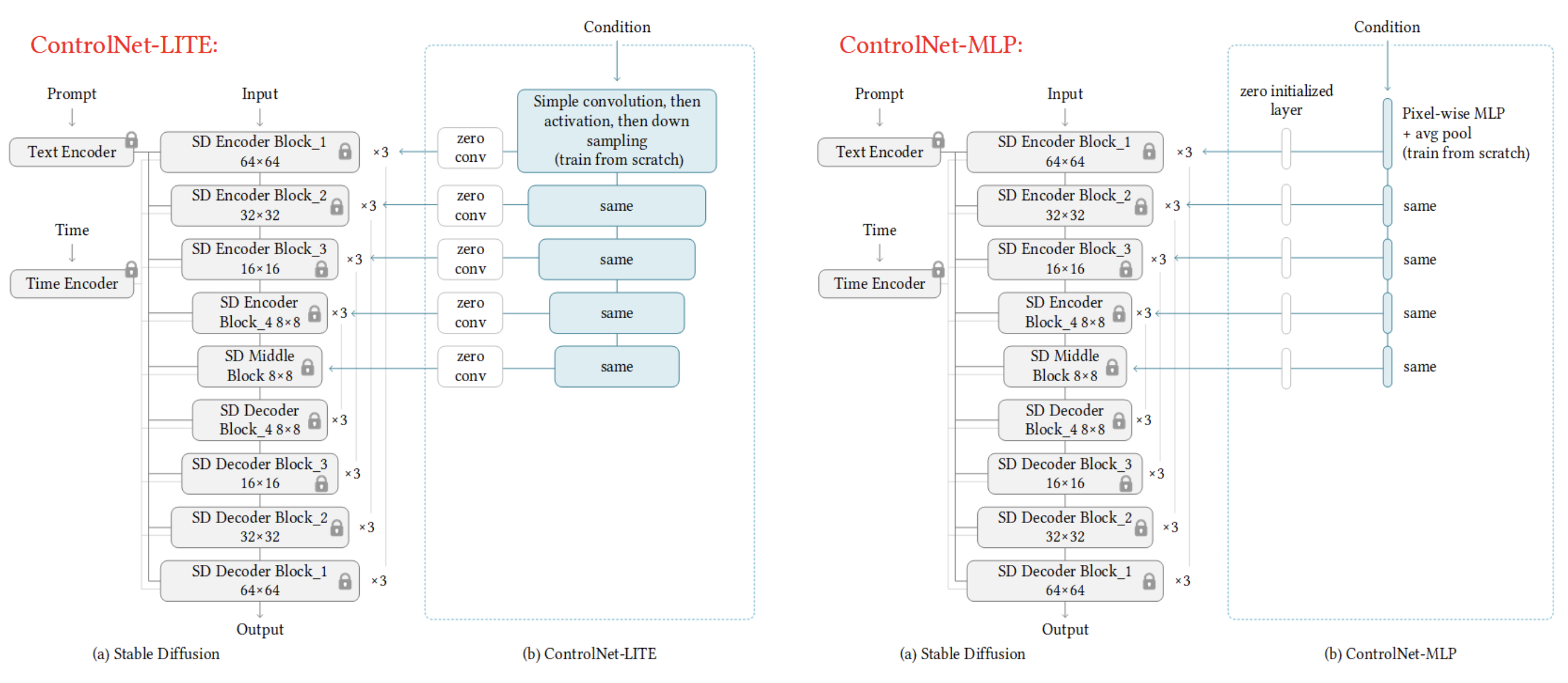
ControlNet-Lite 只使用卷积+下采样对 condition 做处理,生成控制输出再注入到原 UNet,ControlNet-MLP 则是更极端地只使用 MLP + avg pool,参数量大幅减少,两种结构都 train from scratch,测试结论如下:
- 在输入合适的 Prompt 情况下,轻量的结构也能实现很好的控制,效果和原 ContolNet 差异不大
- 将 Prompt 置空,则轻量结构的生成质量大幅下降:

上图左上是输入的 condition 图,右上是 Paper 中原 ControlNet 的结果,在没有 Prompt 输入情况下,也能理解“房子”、“道路”这种语义信息,左下/右下分别是 ControlNet-Lite/MLP 的结果,可以看出虽然空间结构上对齐了 condition,但丢失了语义信息,且图像本身也有不少错乱的地方。
因此可以得出结论:从 UNet 中复制 Encoder,能保持 ControlNet 的语义理解能力,当然如果只需要空间对齐,轻量结构也是可行的。这个实验也进一步论证了零卷积的重要性,如果没有零卷积,刚开始训练时经过几个 step 后,可能复制出来的 Encoder 的参数就会被破坏得很厉害,要达到之前的语义理解能力,就相当于从头开始训 SD,大大增加了训练成本。
更详细的讨论可以查看原帖: Ablation Study: Why ControlNets use deep encoder? What if it was lighter? Or even an MLP?,另外有篇文章也进行了相关实验:ControlNetLite — Smaller and Faster ControlNet?
2. Precomputed ControlNet
如下图,该方案是训练时逐步断开 input 和 condition 的连接,从而在推理时只需提前执行一次 ControlNet,而不是在 Denoising Loop 中每次都执行
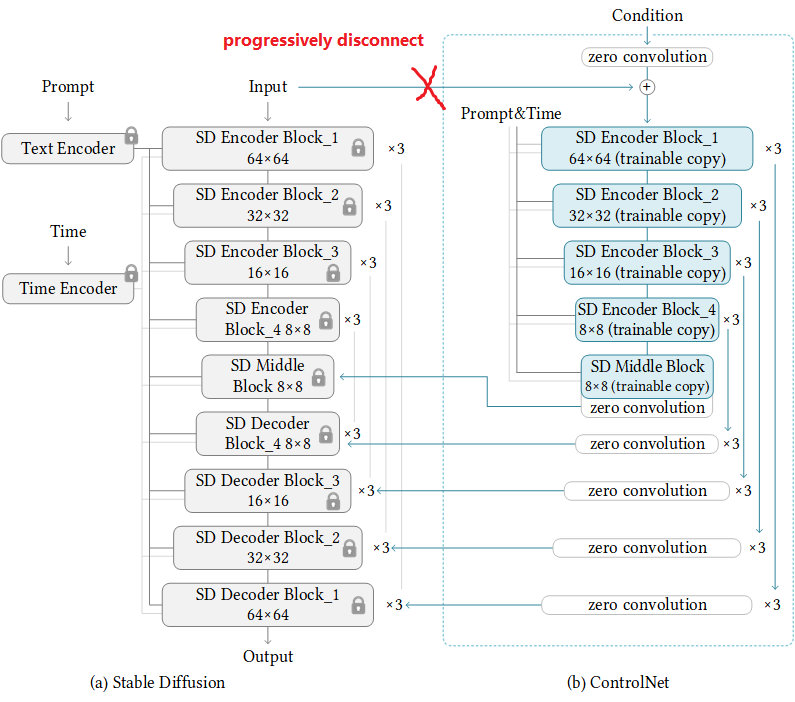
不过结论是效果达不到原来的 ControlNet,出图质量降低,原帖:[Precomputed ControlNet] Speed up ControlNet by 45% – but is it necessary?
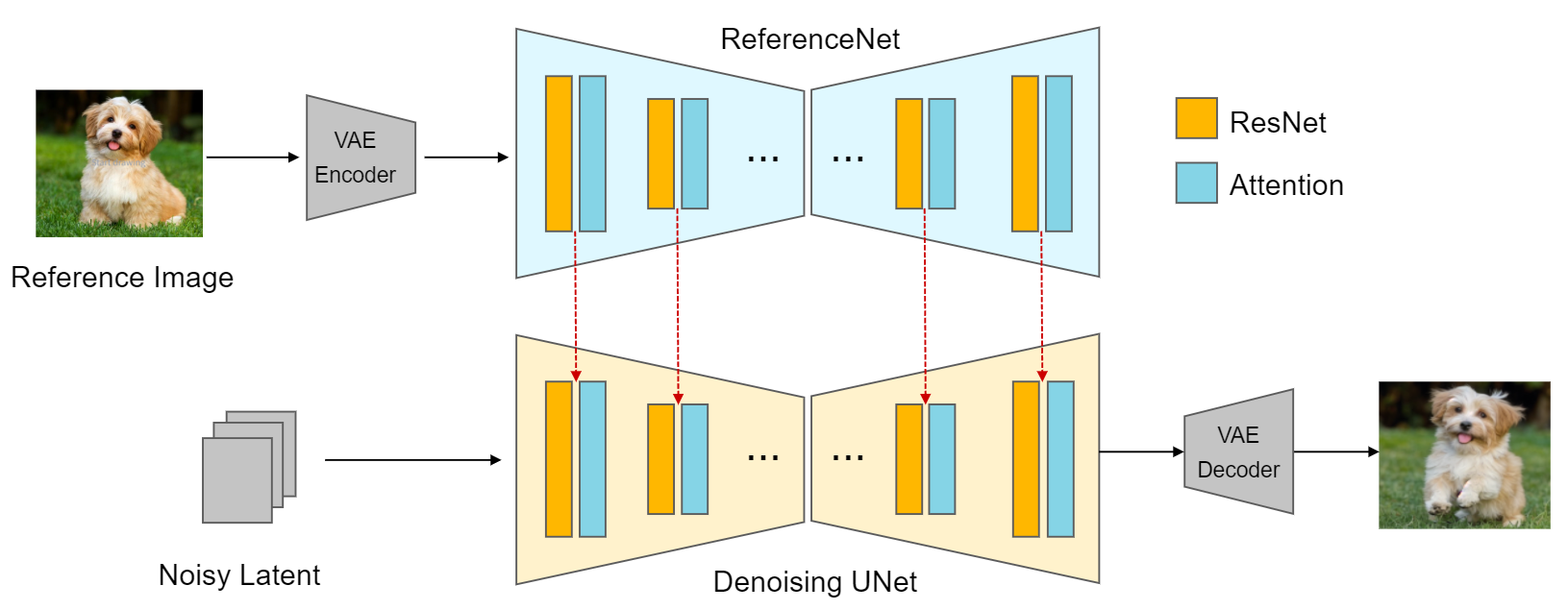
3. Reference-Only/AdaIN
ControlNet 作者之后又提出了 Reference-Only/AdaIN 的方案,实现了不需要额外模型的条件控制,如下图,两个 UNet 实际上是复用同一个模型执行两遍,当然这种控制效果和 ControlNet 有些不一样,不再强调空间结构的对齐,更详细的介绍可以查看:ReferenceNet 简介及相关算法整理
ControlNet 代码解释(Diffusers)
Hugging Face Diffusers 中 关于 ControlNet 的实现主要有三个地方:
- ControlNetModel:包含 ControlNet 的模型结构,init 和 forward 实现
- UNet2DConditionModel:包含 ControlNet 输出添加到 UNet 中的实现
- StableDiffusionControlNetPipeline:推理流程串联
另外还有 ControlNet 的训练示例代码:train_controlnet.py、train_controlnet_sdxl.py
ControlNetModel
首先是 ControlNet 的输出,包含 down block 列表和 mid block,用于添加到原 UNet
class ControlNetOutput(BaseOutput):
down_block_res_samples: Tuple[torch.Tensor]
mid_block_res_sample: torch.Tensor然后是对 ControlNet 输入条件图的处理:
class ControlNetConditioningEmbedding(nn.Module):
def __init__(
self,
conditioning_embedding_channels: int,
conditioning_channels: int = 3,
block_out_channels: Tuple[int, ...] = (16, 32, 96, 256),
):
super().__init__()
self.conv_in = nn.Conv2d(conditioning_channels, block_out_channels[0], kernel_size=3, padding=1)
self.blocks = nn.ModuleList([])
for i in range(len(block_out_channels) - 1):
channel_in = block_out_channels[i]
channel_out = block_out_channels[i + 1]
self.blocks.append(nn.Conv2d(channel_in, channel_in, kernel_size=3, padding=1))
self.blocks.append(nn.Conv2d(channel_in, channel_out, kernel_size=3, padding=1, stride=2))
# 零卷积输出
self.conv_out = zero_module(
nn.Conv2d(block_out_channels[-1], conditioning_embedding_channels, kernel_size=3, padding=1)
)
def forward(self, conditioning):
embedding = self.conv_in(conditioning)
embedding = F.silu(embedding)
for block in self.blocks:
embedding = block(embedding)
embedding = F.silu(embedding)
embedding = self.conv_out(embedding)
return embedding可以看到其主要是几层 Conv2d,用来将输入图转为 feature map ,并在最后通过zero_module添加了一个零卷积
def zero_module(module):
for p in module.parameters():
nn.init.zeros_(p)
return module接下来是 ControlNetModel 的初始化,主要包含从 UNet 复制结构和权重的逻辑,以及在各个block后添加零卷积的逻辑:
def from_unet(
cls,
unet: UNet2DConditionModel,
controlnet_conditioning_channel_order: str = "rgb",
conditioning_embedding_out_channels: Optional[Tuple[int, ...]] = (16, 32, 96, 256),
load_weights_from_unet: bool = True,
conditioning_channels: int = 3,
):
# 从 unet 读取一些参数
transformer_layers_per_block = (
unet.config.transformer_layers_per_block if "transformer_layers_per_block" in unet.config else 1
)
encoder_hid_dim = unet.config.encoder_hid_dim if "encoder_hid_dim" in unet.config else None
...
# 创建 controlnet 对象
controlnet = cls(...)
# 从 unet 复制权重
if load_weights_from_unet:
controlnet.conv_in.load_state_dict(unet.conv_in.state_dict())
controlnet.time_proj.load_state_dict(unet.time_proj.state_dict())
...
# 复制 down_blocks 权重
controlnet.down_blocks.load_state_dict(unet.down_blocks.state_dict())
# 复制 mid_block 权重
controlnet.mid_block.load_state_dict(unet.mid_block.state_dict())
return controlnetdef __init__(
self,
...
):
super().__init__()
...
# input
conv_in_kernel = 3
conv_in_padding = (conv_in_kernel - 1) // 2
self.conv_in = nn.Conv2d(
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
)
# 初始化 time, class embedding
...
# 初始化条件输入embedding
self.controlnet_cond_embedding = ControlNetConditioningEmbedding(
conditioning_embedding_channels=block_out_channels[0],
block_out_channels=conditioning_embedding_out_channels,
conditioning_channels=conditioning_channels,
)
self.down_blocks = nn.ModuleList([])
self.controlnet_down_blocks = nn.ModuleList([])
# down
output_channel = block_out_channels[0]
# 添加到 down block 后的零卷积
controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
controlnet_block = zero_module(controlnet_block)
self.controlnet_down_blocks.append(controlnet_block)
self.down_blocks = ...
# mid
mid_block_channel = block_out_channels[-1]
# 添加到 mid block 后的零卷积
controlnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
controlnet_block = zero_module(controlnet_block)
self.controlnet_mid_block = controlnet_block
self.mid_block = ...最后是 forward 实现,中间的 down、mid 层逻辑与 UNet 一致,区别主要是最后多了零卷积处理,并乘以scale系数
def forward(
self,
...
) -> Union[ControlNetOutput, Tuple[Tuple[torch.FloatTensor, ...], torch.FloatTensor]]:
# 1. time
timesteps = timestep
emb = ...
# 2. pre-process
sample = self.conv_in(sample)
# 从输入条件图提取 feature map,并 Add 到 sample
controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
sample = sample + controlnet_cond
# 3. down
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
down_block_res_samples += res_samples
# 4. mid
if self.mid_block is not None:
sample = self.mid_block(sample, emb)
# 5. Control net blocks
# 将前面的 down、mid 输出再输入到零卷积
controlnet_down_block_res_samples = ()
for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
down_block_res_sample = controlnet_block(down_block_res_sample)
controlnet_down_block_res_samples = controlnet_down_block_res_samples + (down_block_res_sample,)
down_block_res_samples = controlnet_down_block_res_samples
mid_block_res_sample = self.controlnet_mid_block(sample)
# 6. scaling
mid_block_res_sample = mid_block_res_sample * conditioning_scale
...
if not return_dict:
return (down_block_res_samples, mid_block_res_sample)
return ControlNetOutput(
down_block_res_samples=down_block_res_samples, mid_block_res_sample=mid_block_res_sample
)UNet2DConditionModel
unet 主要是 forward 中涉及对 ControlNet 输出的处理:
def forward(
self,
...
# ControlNet 结果输入
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
mid_block_additional_residual: Optional[torch.Tensor] = None,
...
) -> Union[UNet2DConditionOutput, Tuple]:
...
# 判断是否用到了 ControlNet
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
...
# 3. down
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
down_block_res_samples += res_samples
# down 层的输出处理:down_block_res_samples = down_block_res_samples + down_block_additional_residuals
if is_controlnet:
new_down_block_res_samples = ()
for down_block_res_sample, down_block_additional_residual in zip(
down_block_res_samples, down_block_additional_residuals
):
down_block_res_sample = down_block_res_sample + down_block_additional_residual
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
down_block_res_samples = new_down_block_res_samples
# 4. mid
if self.mid_block is not None:
sample = self.mid_block(sample, emb)
# mid 层的输出处理:sample = sample + mid_block_additional_residual
if is_controlnet:
sample = sample + mid_block_additional_residual
# 5. up
...StableDiffusionControlNetPipeline
pipeline 中的实现,主要是去噪过程增加对 controlnet 的调用:
for i, t in enumerate(timesteps):
...
# 输入给 controlnet 的文本 embedding
if guess_mode and self.do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
# controlnet scale 处理
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
# 调用 controlnet 模型推理,得到 down_block_res_samples, mid_block_res_sample
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
return_dict=False,
)
# 将 controlnet 的输出设置到 unet (down_block_res_samples、mid_block_res_sample)
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
timestep_cond=timestep_cond,
cross_attention_kwargs=self.cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
...ControlNet 训练
diffusers 代码中提供了 ControlNet 完整的训练示例,包括 SD1.5 和 SDXL,两者区别不大,先来看 SD1.5 的训练实现:
首先是各个模块的初始化:
# 初始化 tokenizer、noise_scheduler、text_encoder、vae、unet
tokenizer = AutoTokenizer.from_pretrained(...)
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder = text_encoder_cls.from_pretrained(...)
vae = AutoencoderKL.from_pretrained(...)
unet = UNet2DConditionModel.from_pretrained(...)
# 初始化 controlnet,从预训练模型加载,或者从unet中复制
if args.controlnet_model_name_or_path:
logger.info("Loading existing controlnet weights")
controlnet = ControlNetModel.from_pretrained(args.controlnet_model_name_or_path)
else:
logger.info("Initializing controlnet weights from unet")
controlnet = ControlNetModel.from_unet(unet)
# 只训练 controlnet
vae.requires_grad_(False)
unet.requires_grad_(False)
text_encoder.requires_grad_(False)
controlnet.train()然后是 Optimizer、Dataloader、lr_scheduler 的初始化:
# Optimizer creation
params_to_optimize = controlnet.parameters()
optimizer = optimizer_class(...)
train_dataset = make_train_dataset(args, tokenizer, accelerator)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
...
)
lr_scheduler = get_scheduler(...)
# Prepare everything with our `accelerator`.
controlnet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
controlnet, optimizer, train_dataloader, lr_scheduler
)最后是 Diffusion 的加噪训练:
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(controlnet):
# 将结果图转为 latents
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# 生成随机噪声
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# 生成随机 t
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# 通过 scheduler 进行加噪
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# 文本 embedding
encoder_hidden_states = text_encoder(batch["input_ids"], return_dict=False)[0]
# 输入条件图
controlnet_image = batch["conditioning_pixel_values"].to(dtype=weight_dtype)
# 调用 controlnet 生成 down_block_res_samples, mid_block_res_sample
down_block_res_samples, mid_block_res_sample = controlnet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
controlnet_cond=controlnet_image,
return_dict=False,
)
# 调用 unet 预测噪声(设置 down_block_additional_residuals、mid_block_additional_residual)
model_pred = unet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
down_block_additional_residuals=[
sample.to(dtype=weight_dtype) for sample in down_block_res_samples
],
mid_block_additional_residual=mid_block_res_sample.to(dtype=weight_dtype),
return_dict=False,
)[0]
# 计算 loss
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
# 反向传播更新权重
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=args.set_grads_to_none)这里注意输入给 ControlNet 的 Prompt 置空一部分,有利于在没有prompt的时候,更好的挖掘控制条件中的信息(例如边缘,深度等)
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if random.random() < args.proportion_empty_prompts:
captions.append("") # 置空
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids另外可以设置一些参数降低显存占用:
- –mixed_precision:启用混合精度(fp16、bf16)
- –use_8bit_adam:启用 8bit Adam 优化器
- –enable_xformers_memory_efficient_attention:启用 xformers 优化
SDXL 的 ControlNet 训练整体与 SD1.5 类似,区别主要是 SDXL 新增的 embedding:
- pooled text embedding:Prompt 整体语义
- original size、target size:尺度信息
- crop top-left coord:裁剪参数
具体可查看 compute_embeddings 函数的实现。