December 28, 2024
前段时间比较闲,正好在学习 AI 相关的东西,决定用 C++ 写一个神经网络训练框架,类似于图形学的入门项目软件渲染器,不依赖第三方库,从零开始实现,目标是能进行 MNIST 训练,经过几周的投入,目前算是初步完成了,代码已放到 Github:
https://github.com/keith2018/TinyTorch
之前的一些手写项目:
框架
项目基于 C++ 实现,可选依赖 OpenBLAS 进行矩阵乘法加速(gemm),可通过 cmake 参数 -DUSE_BLAS=ON/OFF 来开关,无其它三方依赖。C++ 类/接口主要模拟 PyTorch 的 API,包括 Tensor/Function/Module/Loss/Optimizer/Scheduler/Dataset/DataLoader 等,麻雀虽小,五脏俱全,demo 目录有几个示例程序,包括 MNIST 的完整训练代码 demo/demo_mnist.cpp。
下面是 C++ 版的 MNIST 模型定义,与 PyTorch 写法类似,区别主要是多了手动 registerModules()(目前还不能自动注册):
class Net : public nn::Module {
public:
Net() {
registerModules({conv1, conv2, dropout1, dropout2, fc1, fc2});
}
Tensor forward(Tensor &x) override {
x = conv1(x);
x = Function::relu(x);
x = conv2(x);
x = Function::relu(x);
x = Function::maxPool2d(x, 2);
x = dropout1(x);
x = Tensor::flatten(x, 1);
x = fc1(x);
x = Function::relu(x);
x = dropout2(x);
x = fc2(x);
x = Function::logSoftmax(x, 1);
return x;
}
private:
nn::Conv2D conv1{1, 32, 3, 1};
nn::Conv2D conv2{32, 64, 3, 1};
nn::Dropout dropout1{0.25};
nn::Dropout dropout2{0.5};
nn::Linear fc1{9216, 128};
nn::Linear fc2{128, 10};
};自动微分的实现如下图所示:
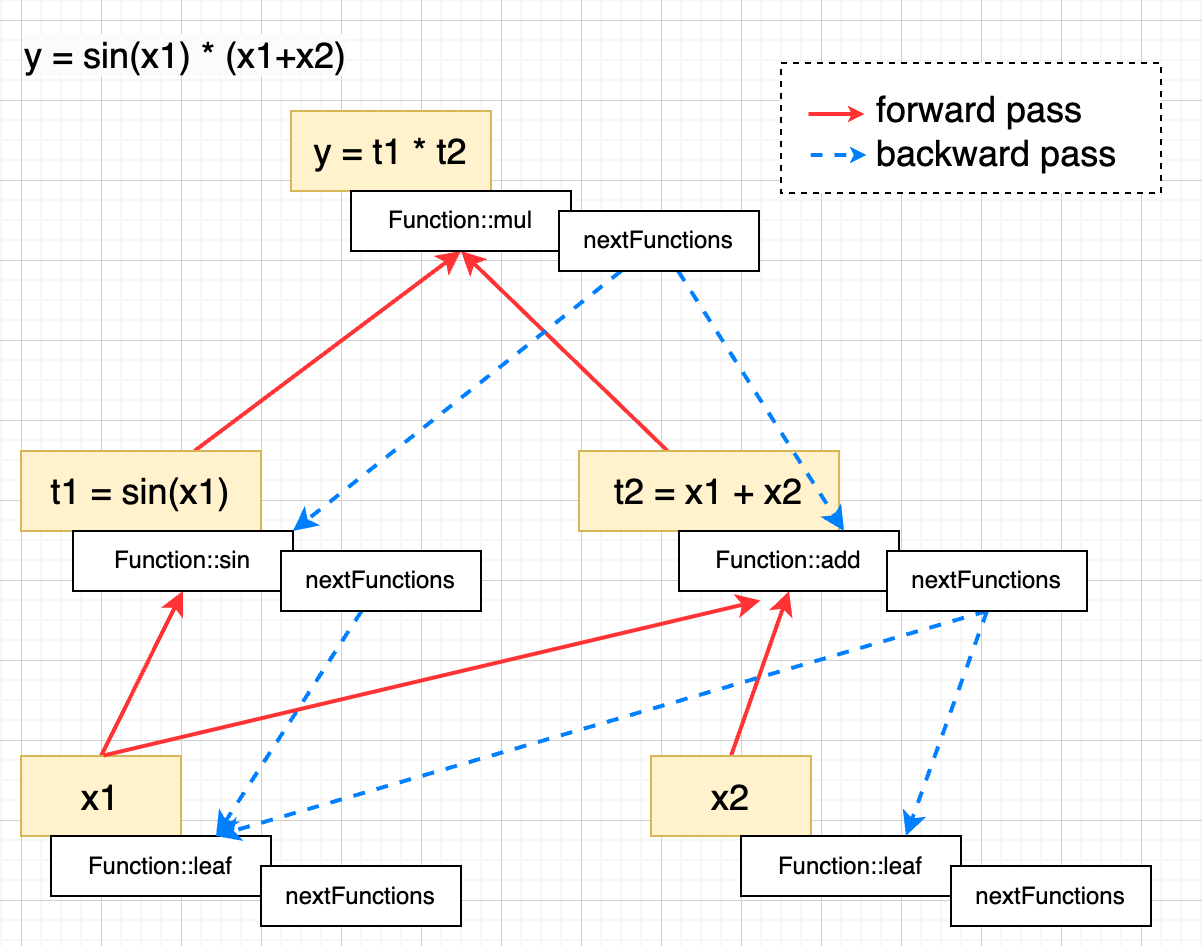
对 Tensor 的计算都是通过 Function 来实现,不同的 Function 需要实现各自的 forward() 和 backward() 方法,Function 中通过 nextFuncs_ 字段记录依赖关系,也就是说 Function 充当了计算图节点的角色,backward() 的时候再根据依赖关系反向遍历,详见 AutogradMeta::backward 函数的实现,自动微分更详细的解释可以参考这篇文章 自动微分(Automatic Differentiation):实现篇
Tensor
Tensor 实现了 torch.tensor (或 Numpy) 的常用接口,主要有:
- Tensor 创建:shape、zeros、ones、randn、arange、linspace 等
- 维度操作:view、reshape、transpose、squeeze、flatten、index、split、stack 等
- 数学运算:加减乘除、matmul、sum、mean、var、min、max、sin、cos 等
项目里实际上是分成两个类来实现的:TensorImpl 和 Tensor,TensorImpl 只负责基础的张量运算,不涉及梯度相关功能,类似于 torch 的 at::Tensor,上层的 Tensor 再对 TensorImpl 进行包装,添加了梯度、反向传播相关功能实现。
TensorImpl 的数据结构如下:
typedef std::vector<int32_t> Shape;
class TensorImpl {
public:
...
protected:
int32_t dimCount_ = 0;
int32_t elemCount_ = 0;
Shape shape_;
Shape strides_;
float *data_ = nullptr;
};为了简化实现只支持了 float 数值类型,目前是纯 CPU 运算,且没做什么优化,部分接口的实现可能性能不高,如 transpose、reduce、broadcast 等,矩阵乘法 matmul 支持依赖 BLAS 库来加速。
Tensor 类则主要包含了数据 data_ 和梯度信息 gradMeta_,具体的反向传播计算由 AutogradMeta::backward() 完成
class Tensor {
public:
...
private:
bool requiresGrad_ = false;
std::shared_ptr<TensorImpl> data_;
std::shared_ptr<AutogradMeta> gradMeta_ = nullptr;
};
struct AutogradMeta {
void backward(const Tensor &grad);
...
Tensor grad_;
std::shared_ptr<Function> gradFunc_;
...
};Function
Function 除了实现各类算子的 forward() 和 backward(),还充当了计算图节点的角色,计算图的构建由 Function::callForward() 实现:
Tensor Function::callForward(const std::vector<const Tensor*>& inputs) {
auto output = forward(inputs);
auto requiresGrad = false;
for (const auto input : inputs) {
if (input->isRequiresGrad()) {
requiresGrad = true;
break;
}
}
std::shared_ptr<Function> gradFunc = nullptr;
if (NoGradScope::isGradEnabled() && requiresGrad) {
for (const auto input : inputs) {
if (input->isRequiresGrad()) {
nextFuncs_.push_back(input->getGradFunc());
}
}
gradFunc = shared_from_this();
}
return Tensor(std::move(output), requiresGrad, gradFunc);
}Function 目前仅支持单个输出,首先调用子类的 forward() 得到 output,然后判断结果 Tensor 是否需要梯度(任意 input 需要梯度),如果需要梯度,则将所有 input 的 gradFunc 记录到 nextFuncs_ 字段,从而构建了计算图,最后将自身作为 gradFunc 存储到结果 Tensor 中,也就是说 Tensor 的 gradFunc 是生成这个 Tensor 的 Function,而对于叶子节点的 Tensor,其 gradFunc 是特殊的 FuncLeaf,FuncLeaf 不需要 forward(),backward() 则是将梯度写回到 Tensor 中:
TensorImpl FuncLeaf::forward(const std::vector<const Tensor*>& inputs) {
return {};
}
std::vector<TensorImpl> FuncLeaf::backward(const TensorImpl& grad) {
auto retGrad = grad;
auto owner = owner_.lock();
...
*owner->grad_.data_ = retGrad;
return {retGrad};
}Function 目前只实现了训练 MNIST 所必需的一些,如加减乘除、relu、linear、conv2d、softmax 等
Module
Function 本身是不带参数的,Module 则在 Function 的基础上增加了参数管理,主要有如下接口:
class Module {
public:
virtual std::vector<Tensor *> parameters();
virtual std::vector<Tensor *> states();
virtual void zeroGrad();
virtual Tensor forward(Tensor &x);
void eval();
void train(bool mode = true);
};同时 Module 是一个递归结构,Module 本身可以添加子 Module,Module 可以设置 eval 和 train 两种模式,用于区分推理和训练,部分算子在两种模式下有区别,如 Dropout、BatchNorm 等,Module 的参数初始化单独放到了 Init 类中,目前支持 uniform 和 kaimingUniform 两种。
Loss
Loss 也是 Module 的子类,通常 forward() 会有两个输入,同时会有一个 reduction 参数,可以取值 MEAN 或 SUM,目前项目中只实现了 MSELoss 和 NLLLoss
Optimizer
优化器接收 Module 返回的 parameters 参数列表,然后在 step() 中根据梯度更新参数
class Optimizer {
public:
Optimizer(std::vector<Tensor *> &¶meters, float lr, float weightDecay);
void step();
void zeroGrad();
};项目中实现了常用的几种优化器: SGD、Adagrad、RMSprop、AdaDelta、Adam、AdamW 等,参数与 PyTorch 一致,L2 正则化 Weight Decay 作为基础功能放在了 Optimizer 基类中。
Scheduler
Scheduler 主要是用来调节学习率:在 step() 方法中更新 Optimizer 的 lr,作为示例,项目中只实现了 StepLR
class StepLR : public Scheduler {
public:
StepLR(Optimizer &optimizer, int32_t stepSize, float gamma = 0.1, int32_t lastEpoch = -1);
float getLr() override;
private:
int32_t stepSize_;
float gamma_;
};Data
数据相关的接口,项目中模拟实现了 Dataset、DataLoader 和 Transform,Dataset 主要是 size() 和 getItem() 接口,定义如下:
class Dataset {
public:
virtual ~Dataset() = default;
virtual size_t size() const = 0;
virtual std::vector<Tensor> getItem(size_t idx) = 0;
};为方便使用,项目中内置实现了 DatasetMNIST,可直接调用。DataLoader 则接收 dataset、batchSize、shuffle 等作为入参,然后实现迭代器接口,返回 stack 后的 batch 数据
class DataLoader {
public:
DataLoader(const std::shared_ptr<Dataset>& dataset, size_t batchSize,
bool shuffle = false, bool dropLast = false);
class Iterator {
public:
Iterator(const DataLoader& loader, size_t startIdx)
: loader_(loader), batchIdx(startIdx) {}
bool operator!=(const Iterator& other) const;
bool operator==(const Iterator& other) const;
Iterator& operator++();
std::tuple<size_t, std::vector<Tensor>> operator*() const;
private:
const DataLoader& loader_;
size_t batchIdx;
};
Iterator begin() const;
Iterator end() const;
size_t size() const;
};Transform 则是模拟 torchvision.transforms 用于数据处理,同时也模拟了 Compose 将多个 Transform 组合在一起,作为示例,项目中只实现了 Normalize 用于 MNIST 数据的归一化
class Normalize : public Transform {
public:
Normalize(float mean, float std) : mean_(mean), std_(std) {}
Tensor process(Tensor& input) const override;
private:
float mean_;
float std_;
};编译&运行
项目使用 CMake 作为构建工具,自测在 MacOS、Linux、Windows 上都能正常编译运行,如果打开了 USE_BLAS 开关,Linux 上需要提前安装好 OpenBLAS,可以参考文档 OpenBLAS../install.md,顺利的话,demo 跑起来可以看到如下 MNIST 的训练输出:
[DEBUG] demo_mnist ...
[DEBUG] train size: 60000
[DEBUG] test size: 10000
[DEBUG] Train Epoch: 0 [64/60000 0.11%], loss: 2.316415
[DEBUG] Train Epoch: 0 [128/60000 0.21%], loss: 3.804285
[DEBUG] Train Epoch: 0 [192/60000 0.32%], loss: 2.454196
[DEBUG] Train Epoch: 0 [256/60000 0.43%], loss: 2.216763
[DEBUG] Train Epoch: 0 [320/60000 0.53%], loss: 2.127527
[DEBUG] Train Epoch: 0 [384/60000 0.64%], loss: 2.279303
[DEBUG] Train Epoch: 0 [448/60000 0.75%], loss: 2.044209
[DEBUG] Train Epoch: 0 [512/60000 0.85%], loss: 1.981432
[DEBUG] Train Epoch: 0 [576/60000 0.96%], loss: 1.833691
[DEBUG] Train Epoch: 0 [640/60000 1.07%], loss: 1.979517
[DEBUG] Train Epoch: 0 [704/60000 1.17%], loss: 1.928144
[DEBUG] Train Epoch: 0 [768/60000 1.28%], loss: 1.788541