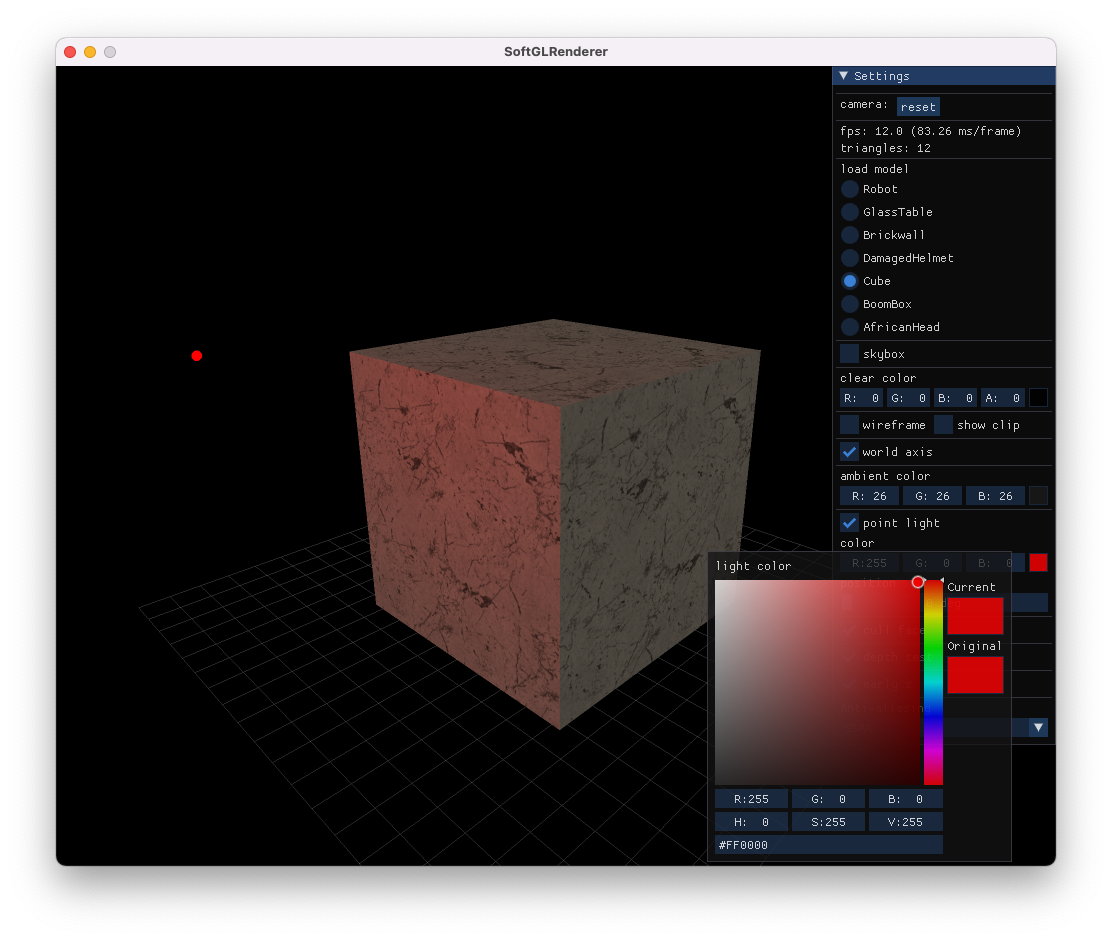
May 18, 2022
Update(2023.03):重构了代码结构,增加了 MSAA 和 ShadowMap 实现,并且增加 OpenGL 和 Vulkan 版本,可运行中实时切换软件渲染器和 OpenGL/Vulkan 渲染器
这是疫情期间业余时间写的一个光栅化软渲染器,C++ 实现,代码地址:
https://github.com/keith2018/SoftGLRender
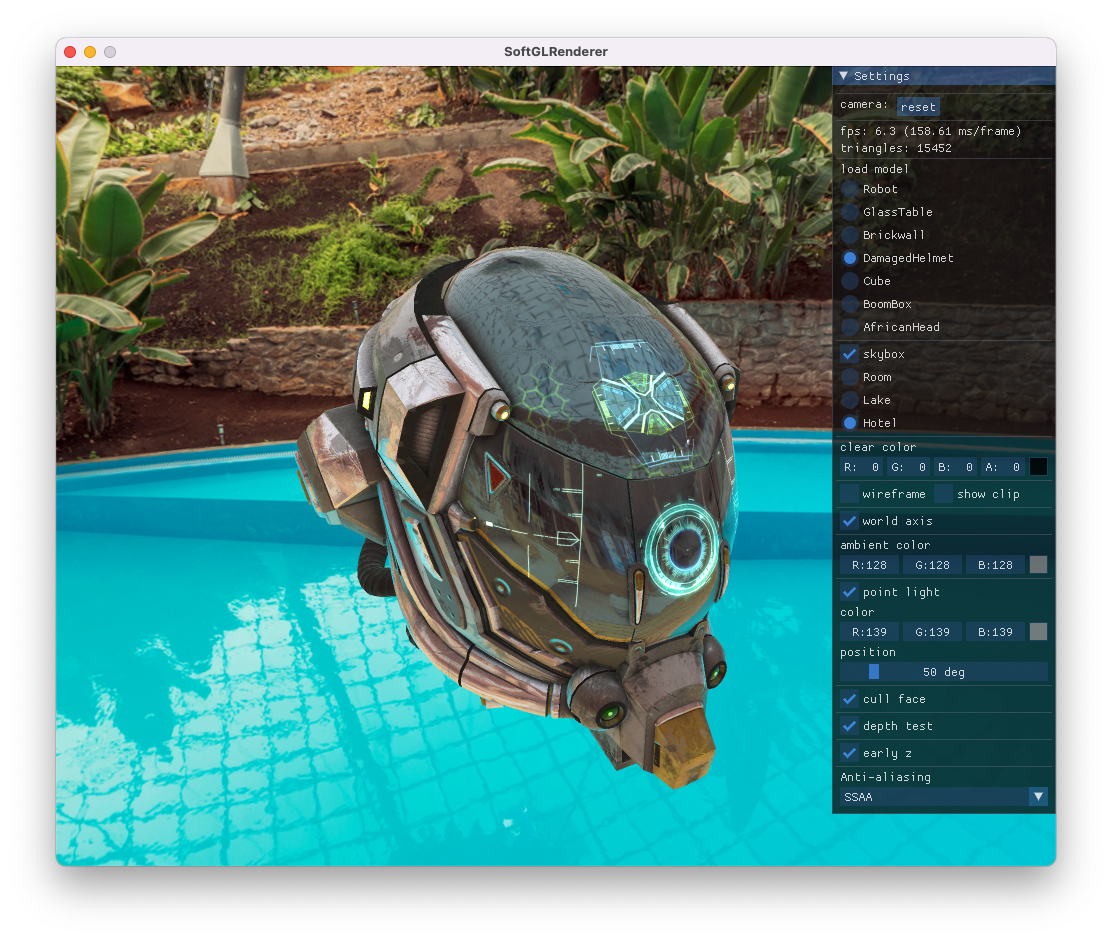
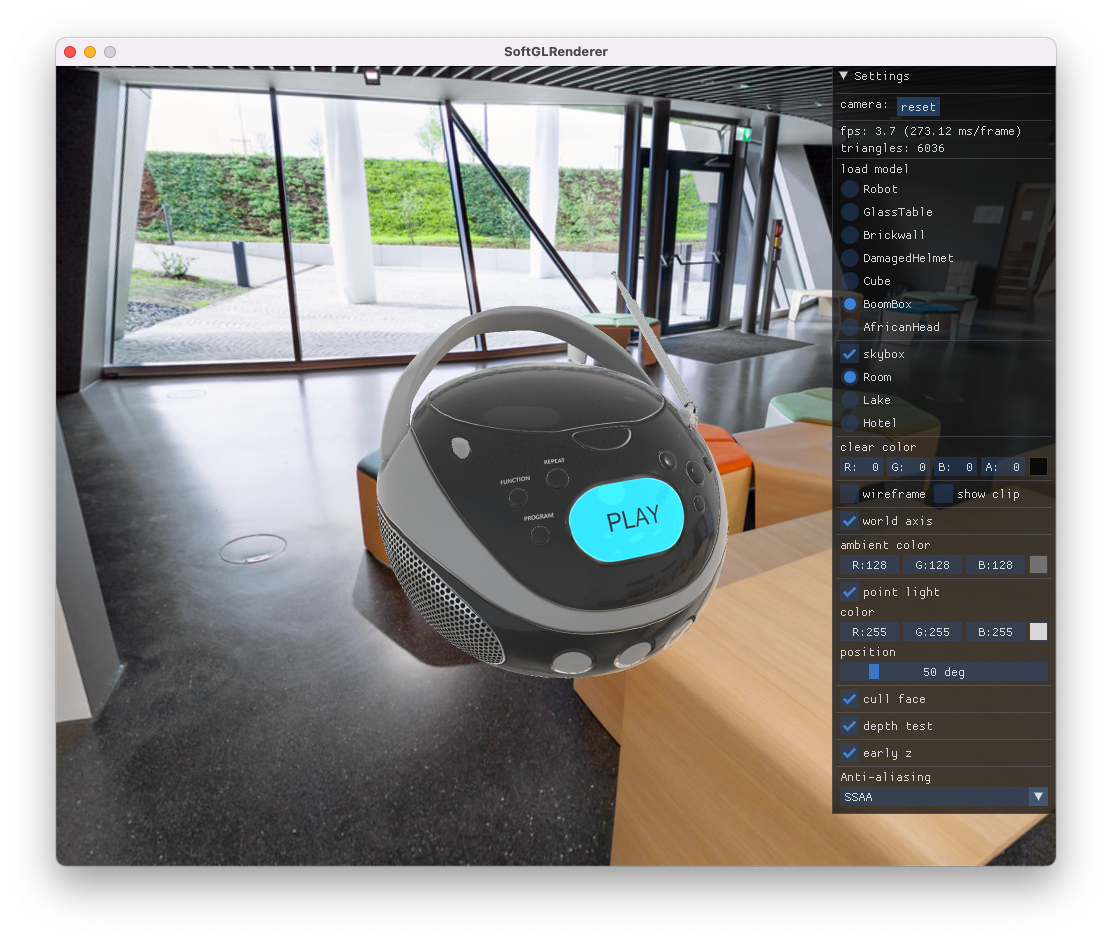
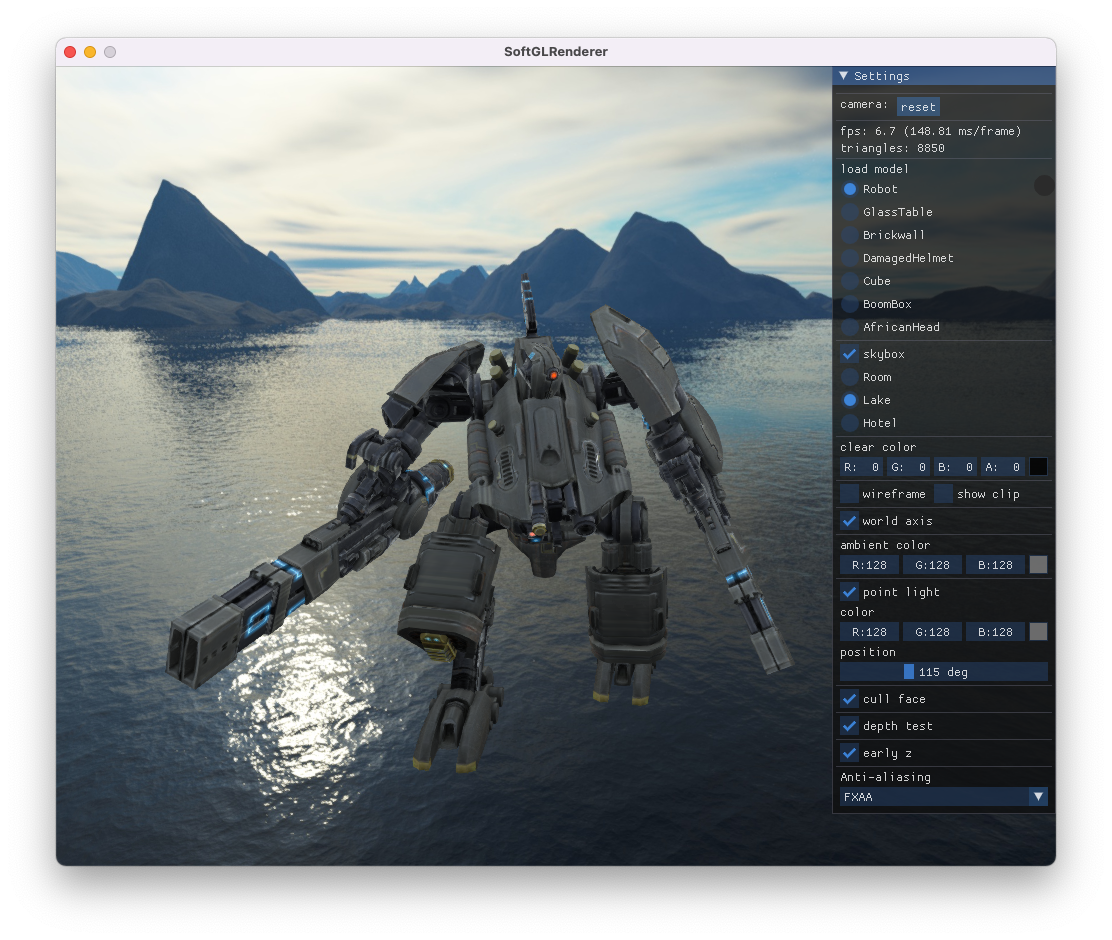
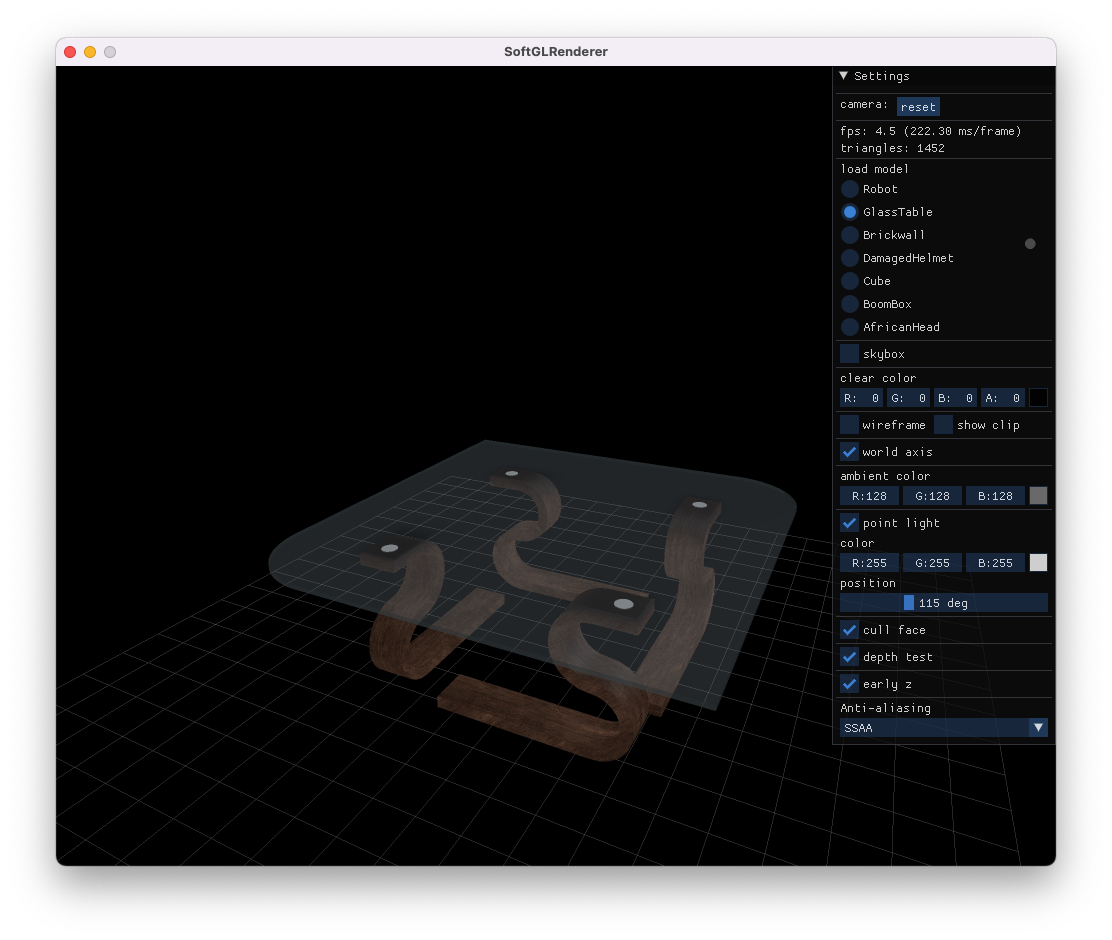
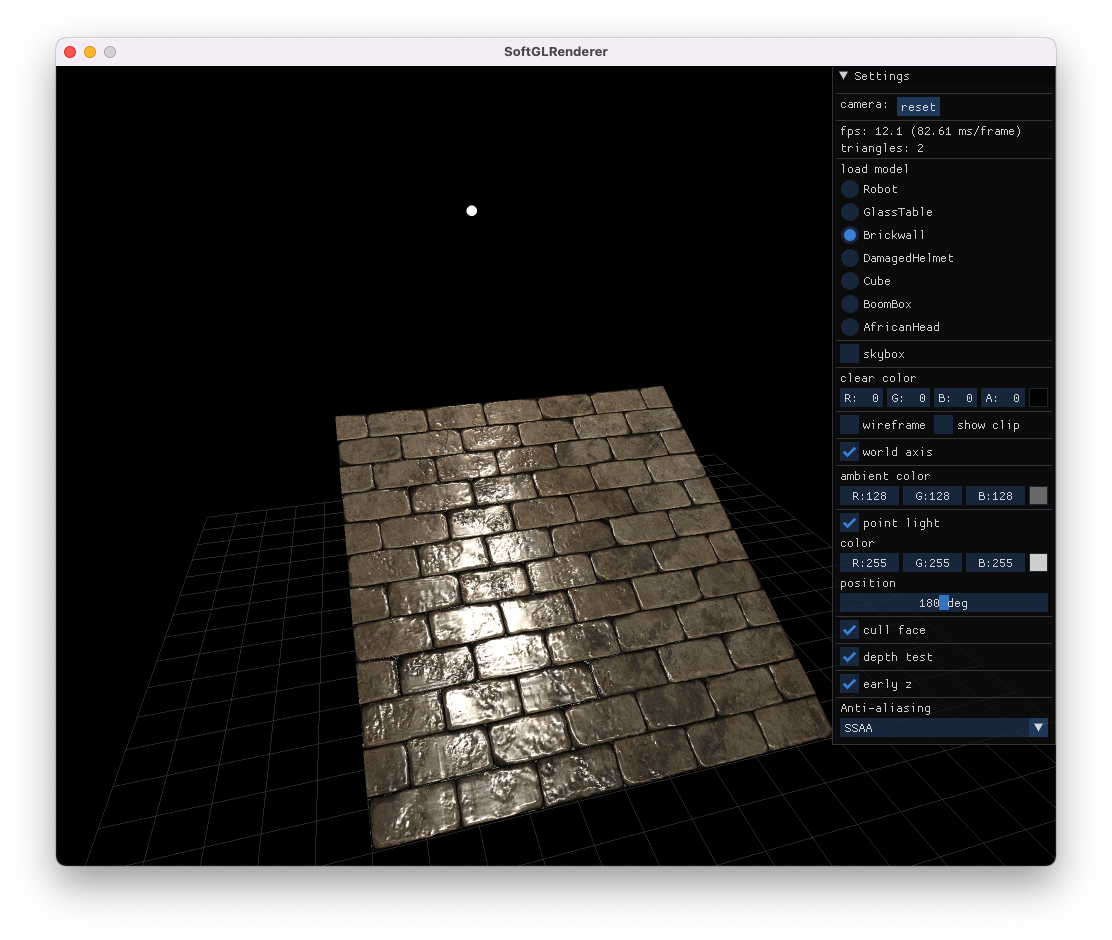
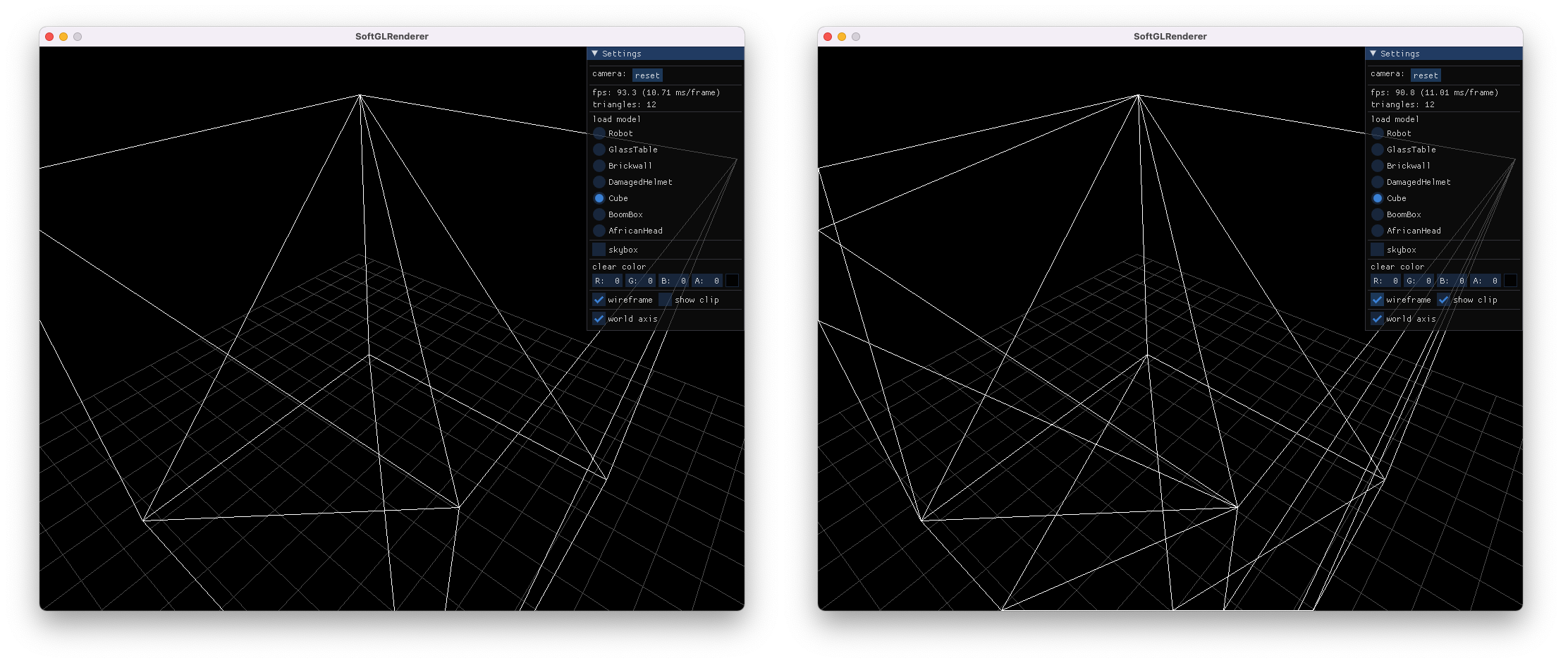
除了带纹理渲染,也支持 wireframe,并且支持查看 frustum 裁剪结果
整体代码量不大,基于C++11,实现了基本的渲染管线流程,并且在渲染器上层加了一些适配逻辑,比如模型加载、相机、设置面板等,使得整个工程可以独立地跑起来,可以方便地加载 GLTF 模型(整个工程也可以看作一个 GLTF Viewer),编译自测过 MacOS、Windows
工程结构
主要有 renderer、shader、app 三个部分:
-
renderer:渲染器实现,输入 Mesh 数据 (Vertex、Indices 等),绑定好自定义的 Shader, 然后启动管线流程,绘制到 FrameBuffer;
-
shader:模拟了可编程渲染管线结构,支持 VertexShader 和 FragmentShader,可以方便地将现有 GLSL 代码改改移植过来跑,工程里内置实现了一些基本的 Shader,如 Blinn-Phong光照、天空盒、PBR&IBL 等;
-
app:这部分主要是 Viewer 层逻辑,包括 GLTF 加载(基于Assimp)、相机 & 控制器、设置面板、不同模型节点渲染 pass 的组织等;
渲染管线
基本的管线流程都有实现:
- Vertex Shading
- View Frustum Culling
- Perspective Divide
- Screen Mapping
- BackFront Culling
- Triangular Rasterization
- Fragment Shading
- Depth Test & Alpha Test
并且简单实现了 Reversed Z、Early Z 这些特性
纹理
实现了常用的纹理 Wrapping 和 Filtering 模式:
- Texture Filtering
- NEAREST
- LINEAR
- NEAREST_MIPMAP_NEAREST
- LINEAR_MIPMAP_NEAREST
- NEAREST_MIPMAP_LINEAR
- LINEAR_MIPMAP_LINEAR
- Texture Wrapping
- REPEAT
- MIRRORED_REPEAT
- CLAMP_TO_EDGE
- CLAMP_TO_BORDER
- CLAMP_TO_ZERO
并且支持了几种常用的纹理参数,如 Lod、Bias、Offset,这里为了支持纹理的 Mipmaps ,渲染器实现了 dFdx、dFdy 的功能,即光栅化是以4个像素为一个 Quad 进行:
/**
* p2--p3
* | |
* p0--p1
*/
PixelContext pixels[4];dFdx、dFdy 就是取相邻像素的 Shader 变量值的差来实现,可以用来在 FS 中求 TBN
纹理的存储支持了三种模式,
- Linear : 逐行存储,通常的图像 RGBA buffer 就是这样的;
- Tiled : 分块存储,块内还是 Linear;
- Morton : 分块存储,块内使用 Morton 模式存储 (类似于 Z 字形);
这里主要是为了提升 Texel Fetch 的缓存命中率从而提升性能,开了天空盒之后,纹理这块的耗时占比很大。
抗锯齿
抗锯齿只加了 SSAA 和 FXAA,SSAA 相对简单,直接渲染器宽高 x2,由于工程里本身是用 OpenGL 的纹理实现的上屏,后面的 resolve 都省了。FXAA 则只需加个后处理 Shader,不影响渲染器结构,实现也不麻烦。经典的 MSAA 后面有时间可以实现一下,会涉及光栅化部分的结构调整。
Shading 模型
实现了 Blinn-Phong 和 PBR-BRDF 两种,不过 PBR 刚开始生成 irradianceMap 和 perfilterMap 确实很慢,会卡一会儿,后面跑起来就还好。
性能优化
这块做的不多,主要有:
- 多线程:光栅化过程采用了多线程分块处理,不过目前的三角形遍历算法还有待优化;
- SIMD:对几个性能瓶颈点做了 SIMD 加速,如重心坐标计算、Shader 的 varying 插值等;
可优化点其实不少,不过软件渲染器主要还是温故下图形基础,就没有过多地搞优化了
渲染样例