September 19, 2021
之前写了个 WebAssembly 虚拟机,经过一番折腾,性能(解析执行)终于接近 Intel 的 WAMR 了,这里总结下其中一个重要的优化点:Threaded Code,其主要优化虚拟机执行时的指令分发性能。首先看一下 WebAssembly 虚拟机的运行流程(解析执行):
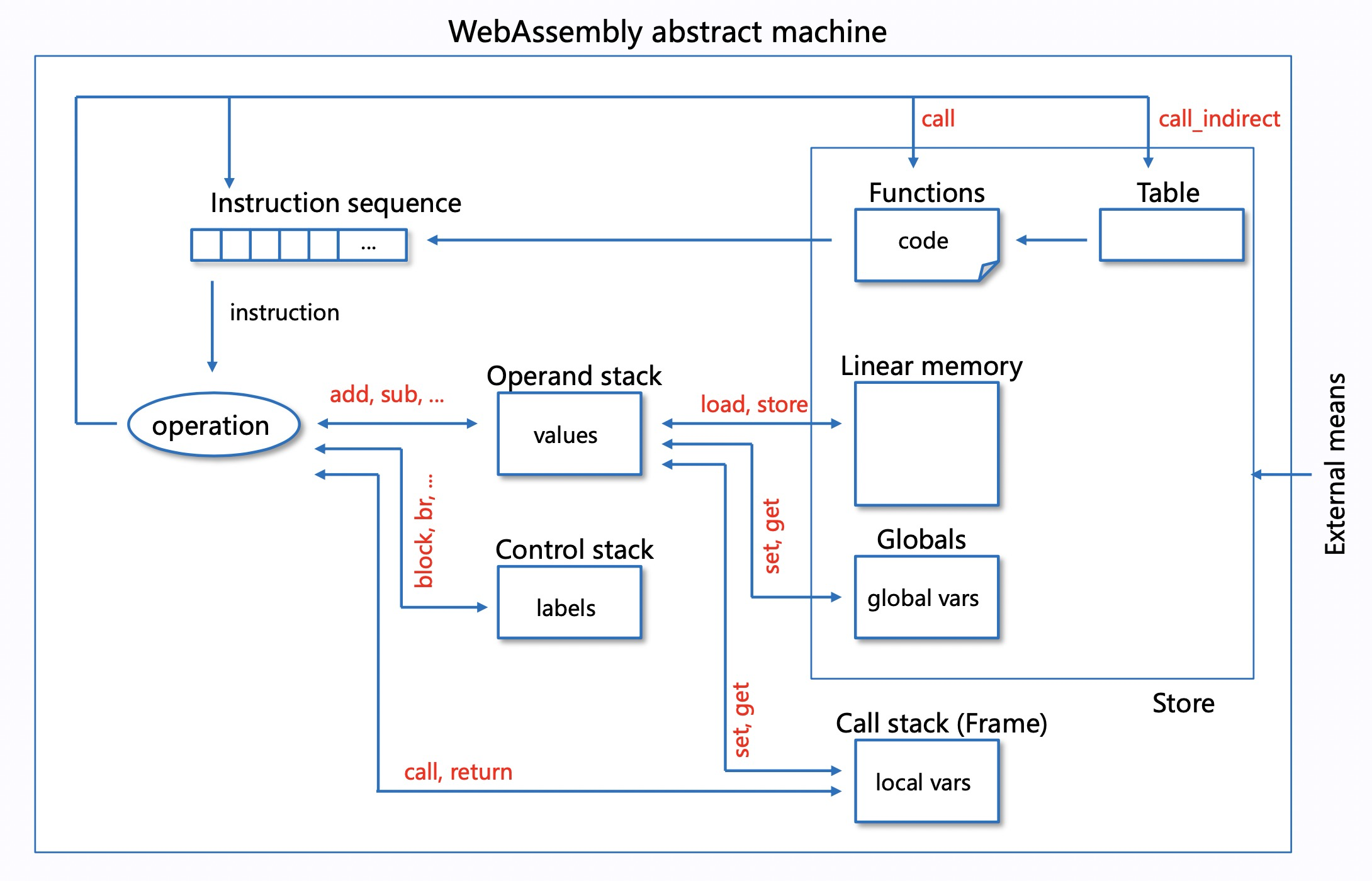
右上部分是程序输入,主要有函数、内存(堆)和全局变量,可以类比代码编译后产生的 binary 文件加载后的内容,函数体(code)则是一个指令序列,虚拟机运行期维护两个栈:Operand stack 和 Control stack,分别存储操作数(values)和代码结构(labels),每个函数调用都会产生一个函数调用帧(Frame),用于存储函数的局部变量(如参数),当各种数据结构都准备就绪,虚拟机从入口函数开始,顺序地执行函数的指令序列,当执行到 call 指令时,会产生新的 Frame,进入新的函数执行。
指令分发
各种解释型语言(如Java、Lua、WebAssembly) 都会定义自己的一套指令集,代码“编译”之后各函数体的内容就是一个指令列表,指令又分控制指令(如跳转、循环、函数调用等)、数值指令(如加减乘除等)、以及内存操作、变量操作相关的指令等等,而虚拟机在运行的时候,“解析执行”的过程实际上就是遍历指令列表,完成每个指令对应的操作。在经典的计算模型里,会有一个程序计数器(pc)指向指令列表的当前位置,每执行完一条指令,pc++,继续下一条指令,这个过程也可以看作是“指令分发”,“Theaded Code” 就是指这样的指令分发形式。
Switch Threading
使用 switch 做指令分发是最直观的,这里为方便测试,我们先定义 OpCode 如下:
typedef enum {
ADD, // *sp += 2
SUB, // *sp -= 1
MUL, // *sp *= 2
DIV, // *sp /= 2
END
} OpCode;然后初始化一段 code,总计 20 亿条指令:
#define CODE_LEN (500000000 * 4)
char *code = new char[CODE_LEN + 1];
for (int i = 0; i < CODE_LEN / 4; i++) {
code[i * 4 + 0] = ADD;
code[i * 4 + 1] = SUB;
code[i * 4 + 2] = MUL;
code[i * 4 + 3] = DIV;
}
code[CODE_LEN] = END;用 switch 做指令分发的实现如下(sp 模拟栈指针,pc 模拟程序计数器):
long test_switch(char *code) {
long ret = 0;
long *sp = &ret;
char *pc = &code[0];
while (true) {
switch (*pc++) {
case ADD: *sp += 2; break;
case SUB: *sp -= 1; break;
case MUL: *sp *= 2; break;
case DIV: *sp /= 2; break;
case END: goto END;
default: break;
}
}
END:
return ret;
}即在一个大循环里,对指令的 OpCode 进行 switch,在每个 case 里完成对应的栈操作,然后进入下一次循环,pc++,继续 switch 操作。编译器对 switch 有不同的优化实现,可参考:https://zhuanlan.zhihu.com/p/38139553
Call Threading
除了 switch,另一种容易想到的方式是函数调用:
typedef void (*OpFunc)(long *);
void add(long *sp) { *sp += 2; }
void sub(long *sp) { *sp -= 1; }
void mul(long *sp) { *sp *= 2; }
void div(long *sp) { *sp /= 2; }
long test_call(char *code) {
long ret = 0;
long *sp = &ret;
char *pc = &code[0];
OpFunc funcs[] = { add, sub, mul, div };
while (*pc != END) {
funcs[*pc++](sp);
}
return ret;
}即每个指令用一个函数来实现,然后将函数地址存入映射表(数组),运行的时候根据 OpCode 找到对应的函数并调用。使用函数调用来分发指令,有利于代码结构的优化,不需要像 switch 那样所有指令实现都写在一起,但函数的 call 涉及栈帧的创建,参数入栈等一系列操作,性能开销并不会理想。
Indirect Threading
GCC 支持 Labels as Values (LLVM 也支持),即可以拿到 label 的地址,得到 void* 类型的值,然后配合 goto,就能运行期动态跳转到不同 label。基于这个特性,虚拟机的指令分发可以有更高效的形式 indirect threading:
long test_indirect(char *code) {
long ret = 0;
long *sp = &ret;
char *pc = &code[0];
void *labels[] = { &&ADD, &&SUB, &&MUL, &&DIV, &&END };
goto *labels[*pc];
ADD:
*sp += 2; goto *labels[*(++pc)];
SUB:
*sp -= 1; goto *labels[*(++pc)];
MUL:
*sp *= 2; goto *labels[*(++pc)];
DIV:
*sp /= 2; goto *labels[*(++pc)];
END:
return ret;
}即不再使用一个大循环来遍历指令列表,而是在每个指令的末尾 goto (同时 pc++) 到下个指令所在 label,直到 END,这里的 indirect 指的是需要根据 pc 的值从数组中找到对应的 label 地址,相应的有 direct threading,pc 的值本身就是 label 地址了,不过实际的项目中,direct threading 可能不方便实现。
尾调用
Indirect threading 方式中,已经不需要大循环来分发指令了,转由指令本身来驱动(pc++), 再看看之前 call threading 的方式,如果在每个函数末尾调用下一个指令的函数,就能省去外面的大循环,转由函数调用来驱动 pc 自增,实现如下:
typedef void (*OpFunc)(long *, char *);
static OpFunc *funcs = nullptr;
#define NEXT pc++; funcs[*pc](sp, pc);
void add(long *sp, char *pc) { *sp += 2; NEXT }
void sub(long *sp, char *pc) { *sp -= 1; NEXT }
void mul(long *sp, char *pc) { *sp *= 2; NEXT }
void div(long *sp, char *pc) { *sp /= 2; NEXT }
void end(long *sp, char *pc) { }
long test_tailcall(char *code) {
long ret = 0;
long *sp = &ret;
char *pc = &code[0];
funcs = new OpFunc[]{ add, sub, mul, div, end };
funcs[*pc](sp, pc);
delete[] funcs;
return ret;
}NEXT 宏定义中,我们将 pc++,然后调用下一个指令函数,这样每执行一个指令都会增加一层函数调用栈,指令多了会导致栈溢出,不过由于调用出现在函数最尾部,编译器是可以进行尾调用优化的,即本来应该进行的函数调用相关操作都可以省略(现场已经没用了),直接跳转到新函数入口地址即可,也即“call”指令优化成了“jmp”指令,从而避免了栈溢出。上面程序如果指定 -O0 优化,运行后会栈溢出报错,指定 -O2 则能正常执行,感兴趣的可以 objdump 看一下优化前后函数生成的指令差异。
寄存器
我们知道从数据的访问速度来看,寄存器 > Cache > 内存,因此如何更充分地利用寄存器、Cache 是虚拟机性能优化的重要方向,如栈顶缓存技术(参考这里),将操作数栈的栈顶元素放到寄存器中,必要的时候再同步到内存,从而省去一些内存操作,但 CPU 的寄存器其实是不方便控制的,特别是如 WebAssembly 这样的基于栈设计的字节码,指令本身并没有寄存器相关信息,虽然虚拟机因此结构简单,兼容性好,执行性能却更难优化,这里基于前面的尾调用优化介绍另一种使用寄存器的方式,该方式也是 wasm3 虚拟机的核心优化原理,示例代码如下:
typedef void (*OpFunc)(long *, char *, long);
static OpFunc *funcs = nullptr;
#define NEXT pc++; funcs[*pc](sp, pc, reg);
void add(long *sp, char *pc, long reg) { reg += 2; NEXT }
void sub(long *sp, char *pc, long reg) { reg -= 1; NEXT }
void mul(long *sp, char *pc, long reg) { reg *= 2; NEXT }
void div(long *sp, char *pc, long reg) { reg /= 2; NEXT }
void end(long *sp, char *pc, long reg) { *sp = reg; }
long test_tailcall_reg(char *code) {
long ret = 0;
long *sp = &ret;
char *pc = &code[0];
funcs = new OpFunc[]{ add, sub, mul, div, end };
funcs[*pc](sp, pc, *sp);
delete[] funcs;
return ret;
}对比“尾调用”的函数实现,我们的加减乘除指令不再操作 sp 指针,而是操作新增的 reg 参数,并将修改后的 reg 变量作为参数传给下一个指令函数,实际上,函数的参数以及函数的局部变量,最终都是当前函数栈帧(Frame)的 locals,编译器会将一部分 locals 优化分配到寄存器以提升性能,不过寄存器数量有限,具体的分配规则要看不同编译器实现,不过参数较少情况下,大部分都会将参数分配到寄存器,我们对比下添加 reg 前后 add 和 sub 函数的编译结果:
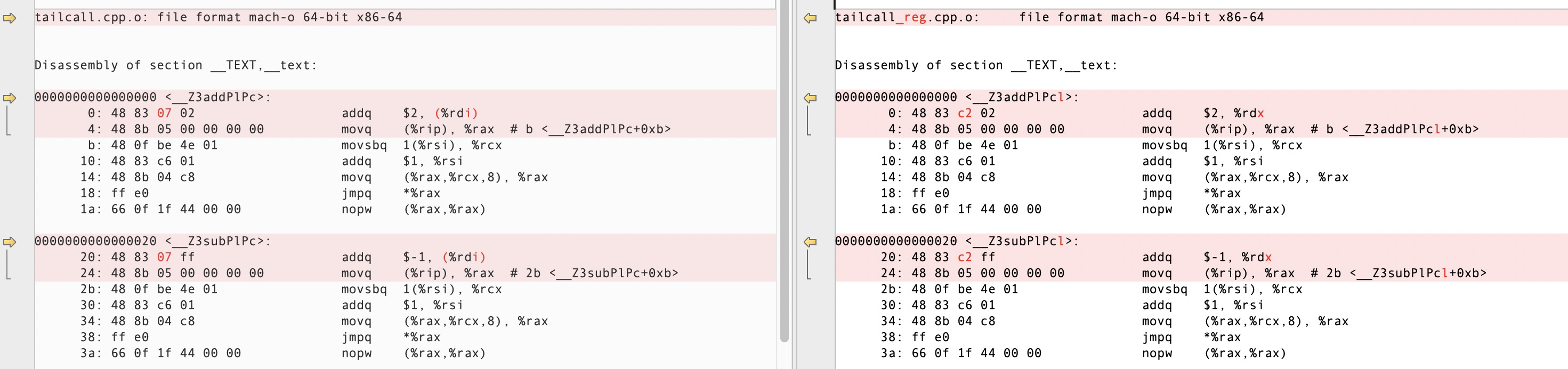
可以看出,函数体的唯一差别是 addq 指令的寻址方式不一样,左边是操作 sp 指针,需要通过寄存器间接访问内存,右边操作 reg 参数,只需要操作寄存器即可,可以从后面的测试数据看到,两者的性能差别巨大。
小结
将以上各种实现进行对比测试,执行前文 Switch Threading 中所述的 20 亿条指令,均开启 -O2 优化,结果如下 (Macbook Pro i7):
switch 2609 ms
indirect 1457 ms
call 2741 ms
tailcall 3184 ms
tailcall_reg 1150 ms可以看出 indirect 和 tailcall + 寄存器优化这俩种实现的性能比较好,当然这个测试并不完全准确,只能反映个大概的性能差别,实际的虚拟机实现还要考虑指令本身的特点以及虚拟机结构等因素,Intel 的 WAMR 引擎使用了 switch 和 indirect 两种方式(根据编译器特性支持),参看代码:wasm_interp_fast.c#L1037
#if WASM_ENABLE_LABELS_AS_VALUES != 0
#define HANDLE_OPCODE(op) &&HANDLE_##op
DEFINE_GOTO_TABLE (const void*, handle_table);
#undef HANDLE_OPCODE
if (exec_env == NULL) {
global_handle_table = (void **)handle_table;
return;
}
#endif
#if WASM_ENABLE_LABELS_AS_VALUES == 0
while (frame_ip < frame_ip_end) {
opcode = *frame_ip++;
#if WASM_CPU_SUPPORTS_UNALIGNED_ADDR_ACCESS == 0
frame_ip++;
#endif
switch (opcode) {
#else
goto *handle_table[WASM_OP_IMPDEP];
#endif而 wasm3 则采用了 tailcall + 寄存器优化,并且前期做了大量的指令优化和寄存器分配工作(m3_compile.c),详见作者自述:How it works,目前 wasm3 仍然是最快的 WASM 解释器,主要还是得益于对寄存器的充分利用。