December 7, 2018
Facebook最近推出了“3D照片”功能,让普通的照片能有3D显示效果:可以随着手机姿态的变化显示照片的不同视角,打开链接即可体验 (手机上陀螺仪控制,PC上鼠标控制)

可以看到虽然视角变化被限制在较小的范围,但是确实有3D的感觉,其实这样结合陀螺仪的简单3D效果也挺常见的,比如王者荣耀的启动界面:
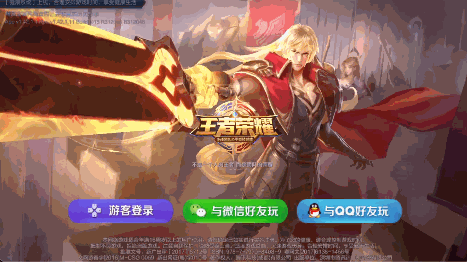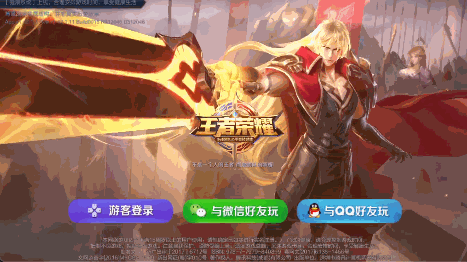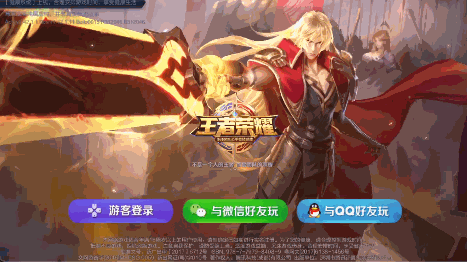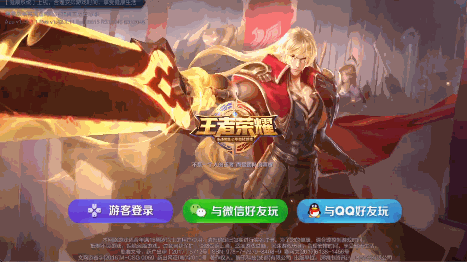
晃动手机,前后景会随着手机姿态位移变化;一些H5页面也有这种效果,实现就更简单了,前后景两张或多张图片层叠,根据陀螺仪数据改变图片相对位置即可
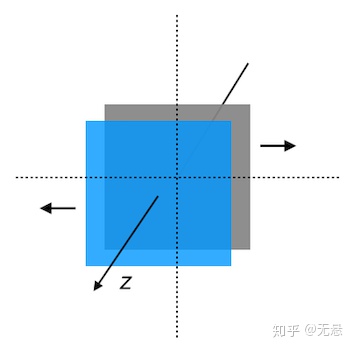
可以看出,产生3D效果的关键在于z轴,即深度(depth),当图层或像素的深度有差别时,就可以在不同视角下计算出图层或像素新的位置,渲染出当前视角对应的图像。我们把每个像素的深度值记录下来,就可以产生与原图同尺寸的“深度图”(Depth Map)

如上左右分别是原图和深度图(实际上是视差图,这里先简单看做深度),用灰度值的差异来表现深度的差异,当然灰度值0~255精度有限,也可以采用彩色的方式。
实时渲染
我们先探讨在已有深度图的情况下,如何实现Facebook 3D照片的效果,即实时地响应陀螺仪或鼠标事件,渲染出不同视角的图像。如前文所述,视角变化需要限制在较小的范围,才能达到可接受的效果,因为我们的输入只有一张图片,缺少原始信息,比如物体的背面(当然用深度学习也是能猜一些出来的)。假设我们的视线沿x轴相对中心点移动d,我们可以粗略地计算像素点的移动D:
D = d * depth * s其中depth为该像素的深度值,s是一个固定的比例因子,这样来看,就非常适合使用shader来实现,实现简单,又能满足实时的效果。
varying vec2 v_texCoord;
uniform sampler2D u_diffuseTexture; // 输入照片
uniform sampler2D u_depthTexture; // 深度图
uniform vec2 u_offset; // 视角偏移
void main(void) {
float scale = 0.05;
float focus = 0.5; // 相对中心点
float map = texture2D(u_depthTexture, v_texCoord).r;
map = map * -1.0 + focus;
vec2 disCords = v_texCoord + u_offset * map * scale; // D = d * depth * s
gl_FragColor = texture2D(u_diffuseTexture, disCords);
}因此只需根据陀螺仪或鼠标事件实时地设置视角偏移u_offset即可。这里推荐一个开源项目depthy, 完整地实现了渲染流程(基于WebGL),支持调整参数,以及一些特效如变焦等。
深度获取
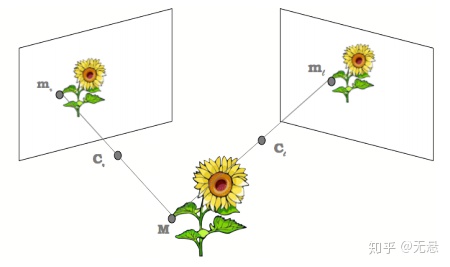
深度图获取是计算机视觉领域的经典问题之一,可以简单地理解为获取场景中物体到相机的距离,总体分为主动被动两大类,主动方法如TOF、结构光、激光等,都是使用设备向场景发射能量,然后用传感器接收,实现深度信息的采集;被动方法最常用的就是双目立体视觉了,通过两个相隔一定距离的相机同时获取同一场景的两幅图像,再使用立体匹配算法找到两幅图像中对应的像素点,随后根据三角原理计算出视差图,视差图再结合相机参数即可得到深度图。
苹果在新技术应用上一直走在行业前列,iPhone 7 Plus、8 Plus都配置了双摄像头,iPhone X更是采用“TrueCamera”,引入了结构光技术
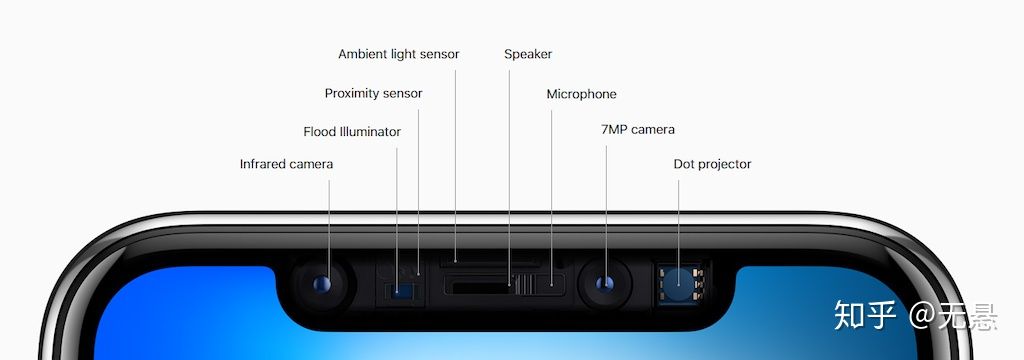
从iOS 11.0开始,苹果在AVFoundation中提供了深度处理相关接口,如AVDepthData
A container for per-pixel distance or disparity information captured by compatible camera devices.
即我们可以通过这些接口从iPhone相机中直接得到深度数据,同时也提供了相机标定数据 AVCameraCalibrationData,包含如内参intrinsicMatrix、外参extrinsicMatrix等,官方提供一篇介绍文档:Capturing Photos with Depth 。有了深度图,还可以方便地实现背景虚化的效果:

"深度"学习
前面介绍的计算机视觉方法获取深度图,都可看作经典方法,根据成像模型,几何计算得出像素点的空间信息,而实际上,想想人眼视觉系统,我们并不能感知物体离眼睛的精确距离,却能轻松感知相对距离,给你张照片,让你确定上面两个点的前后位置关系是很容易的,也许这其中的推理过程我们尚未完全弄清楚,但却是可以借鉴的,很多场景下,相对深度关系已经足够解决问题了。这里不得不想到这几年火起来的深度学习(Deep Learning),是的,深度学习在“深度”方面已经有了一些尝试,用深度学习来学习”深度“,这里介绍CVPR 2018的一篇论文:MegaDepth: Learning Single-View Depth Prediction from Internet Photos
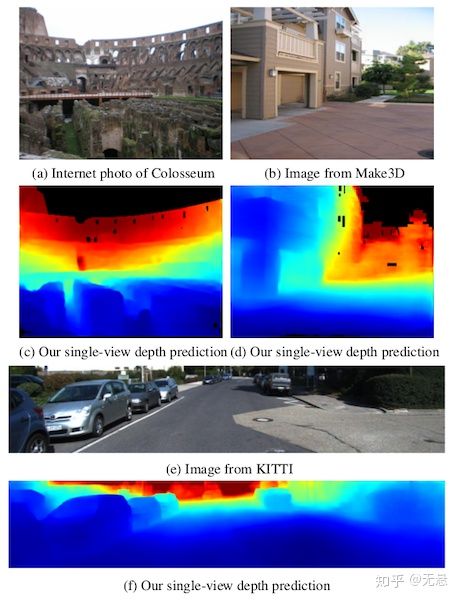
如标题,文章实现的是单张图片的深度预测,论文的一大特点在于其训练集的生成,我们知道常规的图片分类背后都有大量的人工标注,3D深度数据就没这么好生成了,这篇论文用的是经典3D重建方法来生成数据,COLMAP 是一个优秀的重建工具,集成了多个模块(如BA、PMVS/CMVS等),然后为了提高生成数据的质量,论文还提出了一些深度图优化算法,用以弥补COLMAP结果的不足,并且结合了语义分割来做。
通过一张照片就能得到深度图,看起来挺神奇的,最终结果其实还挺不错,这里贴张随手拍的照片跑出来的效果:

应用之前的渲染:

小结
综上,在新的iPhone设备上,我们可以直接获取深度数据,让照片“动”起来,而即使普通的照片,通过深度学习也能实现这一效果。深度数据是2D世界通往3D世界的桥梁,得益于传感器技术的发展,移动端设备的深度采集能力越来越强,另一方面,深度学习也正在让一些"不可能"变得可能。