May 9, 2025
最近重写了 TinyGPT 项目的 Tokenizer 部分,主要是参考了 HuggingFace Tokenizers 的结构,以及 tiktoken 中对 BPE 的优化实现,最终实测性能优于 HuggingFace Tokenizers 和 tiktoken:
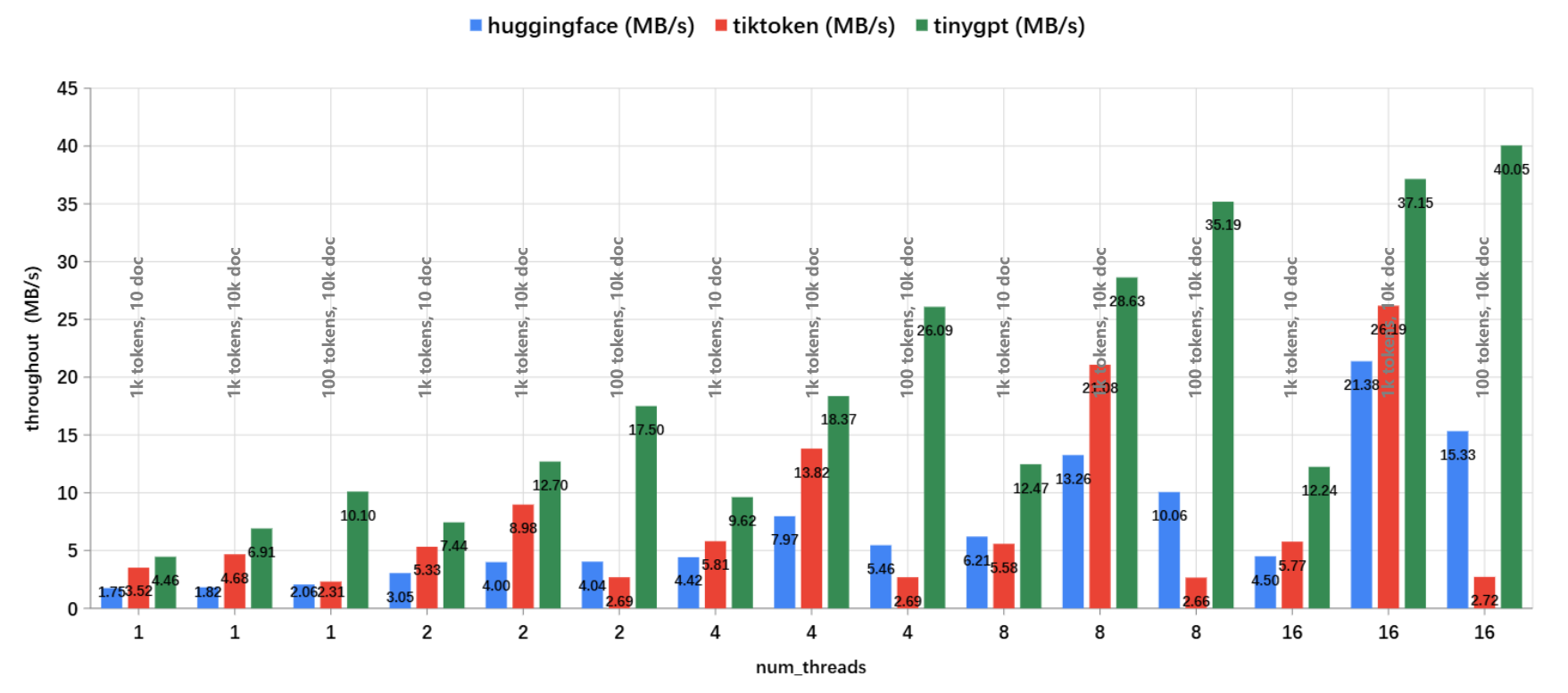
- 评测脚本:~/benches/tokenizer.py
- 机器:Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
Tokenizer 完整代码详见:~/src/tokenizer
分词步骤
Tokenizer 对外主要提供 encode 和 decode 两个方法,分别将字符串映射为 id 序列以及反映射为原字符串,encode 主要由四个步骤组成:
- Normalizer: 对输入字符串进行预处理,比如 Unicode Normalization、大小写转换等;
- Pre-tokenizer: 预分词,通过空格、正则匹配等方式对输入字符串进行拆分,其中
ByteLevel还会进行不可见字符的替换; - Model: 具体的分词算法实现,比如 BPE、WordPiece、Unigram 等;
- Post-Processor: 对结果进行额外处理,如对话模版等;
decode 则相对简单,输入 id 序列映射为原字符串即可。
BPE
BPE 的核心逻辑在于 pair merge,即合并相邻的子串,如下图,输入字符串 "topology",经过 5 次 merge,最终分词结果为 ["to", "po", "logy"]:
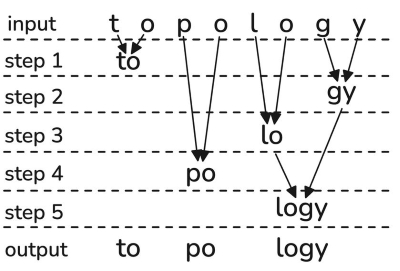
- 首先将输入字符串按字符拆分,构成初始列表 ["t", "o", "p", "o", "l", "o", "g", "y"]
- 根据输入的 mergeRank 字典,查找所有相邻元素的 rank,找到最小的 rank,合并对应的两个元素,列表更新为 ["to", "p", "o", "l", "o", "g", "y"]
- 重复步骤2,直到没有可以再合并的元素
代码实现
从上面的 BPE merge 逻辑可以看出,每次迭代都需要根据所有相邻元素的 rank 求最小 rank,而每次只会合并两个元素,即只会更新两个 rank,自然地可以想到用堆结构来优化,假设字符串长度为 n,需要迭代 m 轮(merge m 次),则普通的实现复杂度为 O(mn),使用堆结构能优化到 O(mlogn)。
不过通常 Pre-Tokenizer split 后的 n 较小,考虑到实现复杂度和缓存命中等因素,tiktoken 中没有使用堆结构,而是用基本的 vector + 遍历来实现:tiktoken/src/lib.rs#_byte_pair_merge
这里我们用 C++ 实现: TinyGPT/src/tokenizer/BPE.cpp#bpeV1
首先使用一个 vector 来存储相邻元素的 rank
struct WordsRank {
uint32_t pos;
uint32_t rank;
};
std::vector<std::string_view> words = splitUTF8(text);
std::vector<WordsRank> ranks(words.size() + 1);其中 text 是经过 ByteLevel 处理后的字符串,WordsRank 的 pos 初始化为 text 中字符的下标,rank 都初始化为最大值:
for (uint32_t i = 0; i < ranks.size(); i++) {
ranks[i].pos = words[i].data() - text.data();
ranks[i].rank = std::numeric_limits<uint32_t>::max();
}
ranks.back().pos = text.size();
ranks.back().rank = std::numeric_limits<uint32_t>::max();然后初始化首轮迭代需要的相邻元素的 rank:
for (uint32_t i = 0; i < ranks.size() - 2; i++) {
ranks[i].rank = getRank(i, i + 1, i + 2);
}接下来进入 while 循环,首先找到最小的 rank 及下标
auto minRank = std::make_pair<uint32_t, uint32_t>(std::numeric_limits<uint32_t>::max(), 0);
for (uint32_t i = 0; i < ranks.size() - 1; i++) {
auto rank = ranks[i].rank;
if (rank < minRank.first) {
minRank = {rank, i};
}
}然后更新最小 rank 下标(实现 merge)及前一个下标对应的 rank
auto minIdx = minRank.second;
ranks[minIdx].rank = getRank(minIdx, minIdx + 2, minIdx + 3);
if (minIdx > 0) {
ranks[minIdx - 1].rank = getRank(minIdx - 1, minIdx, minIdx + 2);
}最后删除最小 rank 下标的后一个元素(被 merge 元素)
ranks.erase(ranks.begin() + (minIdx + 1));迭代完成后,剩余的 ranks 即为所有不能再合并的子串:
std::vector<std::string_view> ret;
ret.reserve(ranks.size() - 1);
for (uint32_t i = 0; i < ranks.size() - 1; i++) {
ret.emplace_back(text.data() + ranks[i].pos, ranks[i + 1].pos - ranks[i].pos);
}在不考虑堆结构情况下,上面实现中的 std::vector::erase 仍存在优化空间,如果用链表,删除元素只需要 O(1) 的复杂度,下面我们用链表来实现:TinyGPT/src/tokenizer/BPE.cpp#bpeV2
首先新增 next 字段来形成单链表:
struct WordsRank {
uint32_t pos;
uint32_t rank;
WordsRank* next;
};接着初始化单链表
for (uint32_t i = 0; i < ranks.size(); i++) {
ranks[i].next = &ranks[i + 1];
}
ranks.back().next = nullptr;然后在 while 循环中,查找最小 rank 的节点和 Prev 节点:
auto minRank = std::numeric_limits<uint32_t>::max();
WordsRank* minRankPtr = nullptr;
WordsRank* minRankPrevPtr = nullptr;
WordsRank* prev = nullptr;
WordsRank* curr = &ranks[0];
while (curr) {
if (curr->rank < minRank) {
minRank = curr->rank;
minRankPtr = curr;
minRankPrevPtr = prev;
}
prev = curr;
curr = curr->next;
}然后进行 merge 操作:
minRankPtr->next = minRankPtr->next->next;更新当前节点和 Prev 节点的 rank:
minRankPtr->rank = getRank(minRankPtr);
if (minRankPrevPtr != nullptr) {
minRankPrevPtr->rank = getRank(minRankPrevPtr);
}使用链表,我们只需要调整指针就实现了删除节点,而不是 O(n) 级别的 std::vector::erase,代价则是多了一个指针的存储空间。
性能优化
简单 Profile 一下可以发现,encode 过程中,最耗时的还是 pre-tokenizer 的正则匹配, 刚开始使用了 Google 的 RE2 来实现,实测下来有这么几个问题:
1、部分正则表达式不支持,比如 \s+(?!\S),只能手动实现才能完美对齐 Python\Rust
2、多线程性能问题,RE2 官方表示多线程友好,多个线程可共用 RE2 对象,但实测性能下降明显,整体耗时并不随着线程数增加而线性减少,解决的办法则是为每个线程创建一个相同的 RE2 对象,类似于 tiktoken 中的实现:
fn _get_tl_regex(&self) -> &Regex {
// See performance notes above for what this is about
// It's also a little janky, please make a better version of it!
// However, it's nice that this doesn't leak memory to short-lived threads
&self.regex_tls[hash_current_thread() % MAX_NUM_THREADS]
}
fn _get_tl_special_regex(&self) -> &Regex {
&self.special_regex_tls[hash_current_thread() % MAX_NUM_THREADS]
}3、初始性能问题,即 RE2 对象在刚开始的几次(主要是前2次)匹配中比较慢,多次匹配后才快起来,目前没找到好的办法
最终还是放弃 RE2 而选择 pcre2,实测开启 jit 后性能非常不错,也能完整支持 gpt2 和 llama3 的正则表达式,具体实现详见:~/src/tokenizer/Regex.cpp
然后就是一些常规优化,比如 HashMap 使用更快的 ankerl::unordered_dense,多线程调度基于无锁队列 moodycamel::ConcurrentQueue 等。