May 7, 2023
AIGC is particularly popular this year, especially with the boom of open source tools related to stable diffusion, it becomes very easy to use or train LORA models. Here is a recording of the first LoRA training I tried recently:
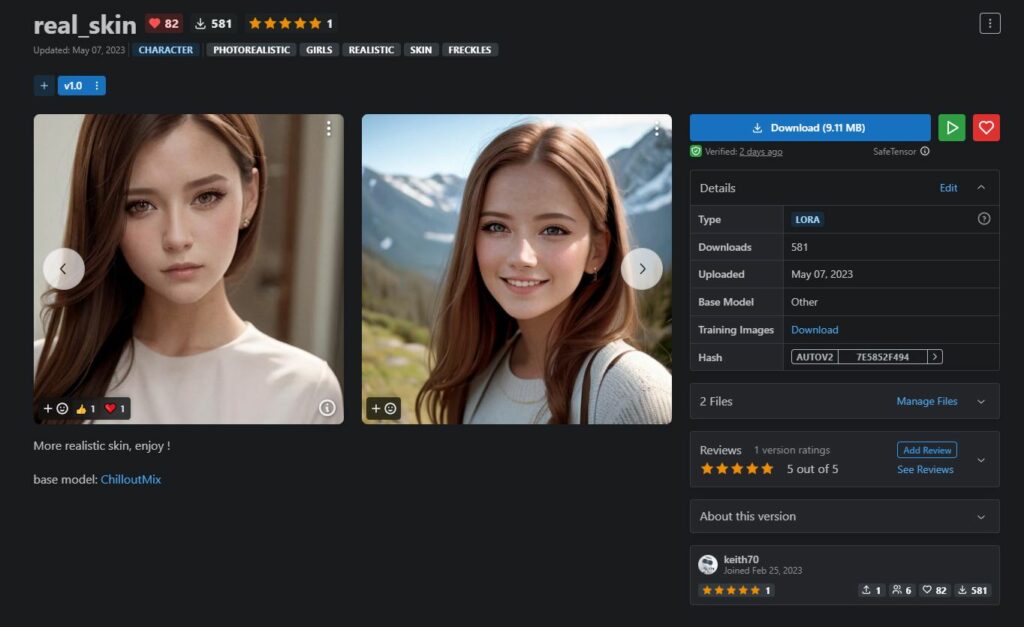
First look at the final results:
 |
 |
 |
 |
The LoRA model has been uploaded to Civital: https://civitai.com/models/60018/realskin (Base Model ChilloutMix)
LoRA Feature
In fact, ChilloutMix itself was very useful in character generation, but there is always a sense of distortion, especially the skin is too smooth and perfect (maybe it is a problem with Prompt?), so I hope to train a LoRA with noise, so that the skin can be more realistic, so name this LoRA model "real_skin", you can compare the difference between without LoRA and with LoRA in the left and right picture below:
 |
 |
Training
The main tools used for training are stable-diffusion-webui and kohya_ss, they are easy to use, fool-like operation, the training machine is Tencent Cloud’s GN7, which is good enough to run LoRA

The preparation of training data is a little tricky: first use ChilloutMix to generate some face images, then use Photoshop to add noise, and then conduct training, so there’s no need to find many noised face pictures. basically, it was just training an effect similar to a "noise filter"

In addition to adding noise, we also cut out the face part of the image to prevent noise from affecting other areas

Here’s the final training images:(already uploaded to Civital)
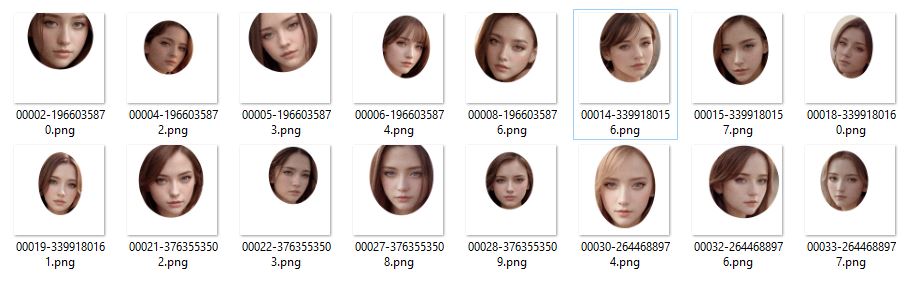
The resolution is 512×512, and the training parameters are as follows:
{
"pretrained_model_name_or_path": "/home/ubuntu/stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors",
"v2": false,
"v_parameterization": false,
"logging_dir": "/home/ubuntu/train/train_lora/log",
"train_data_dir": "/home/ubuntu/train/train_lora/image",
"reg_data_dir": "",
"output_dir": "/home/ubuntu/train/train_lora/model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "cosine",
"lr_warmup": "10",
"train_batch_size": 2,
"epoch": 2,
"save_every_n_epochs": 1,
"mixed_precision": "fp16",
"save_precision": "fp16",
"seed": "",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": "",
"enable_bucket": true,
"gradient_checkpointing": false,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"text_encoder_lr": "5e-5",
"unet_lr": "0.0001",
"network_dim": 8,
"lora_network_weights": "",
"color_aug": false,
"flip_aug": false,
"clip_skip": "1",
"gradient_accumulation_steps": 1.0,
"mem_eff_attn": false,
"output_name": "real_skin",
"model_list": "custom",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "0",
"network_alpha": 1,
"training_comment": "",
"keep_tokens": "0",
"lr_scheduler_num_cycles": "",
"lr_scheduler_power": ""
}The LoRA model generated by the training is about 9MB, upload it to Civital, and call it a day!