October 26, 2025
前段时间给之前写的小玩具 TinyTorch 增加了多卡支持,主要参考 PyTorch c10d 实现了一些基础组件,如 Store、ProgressGroup、Work、Reducer 等,成功跑起来 MNIST 的 DDP 分布式训练,支持单机多卡以及多机多卡,当然对比 PyTorch 做了很多逻辑简化,Backend 也只实现了 NCCL,这里简单介绍一下:
NCCL
NCCL 是 NVIDIA 开源的多卡通信框架,抽象了一系列集群操作接口,比如 all reduce、broadcast 等等,更上层的分布式应用(DP\DDP\TP等)都可以基于这些标准接口来实现
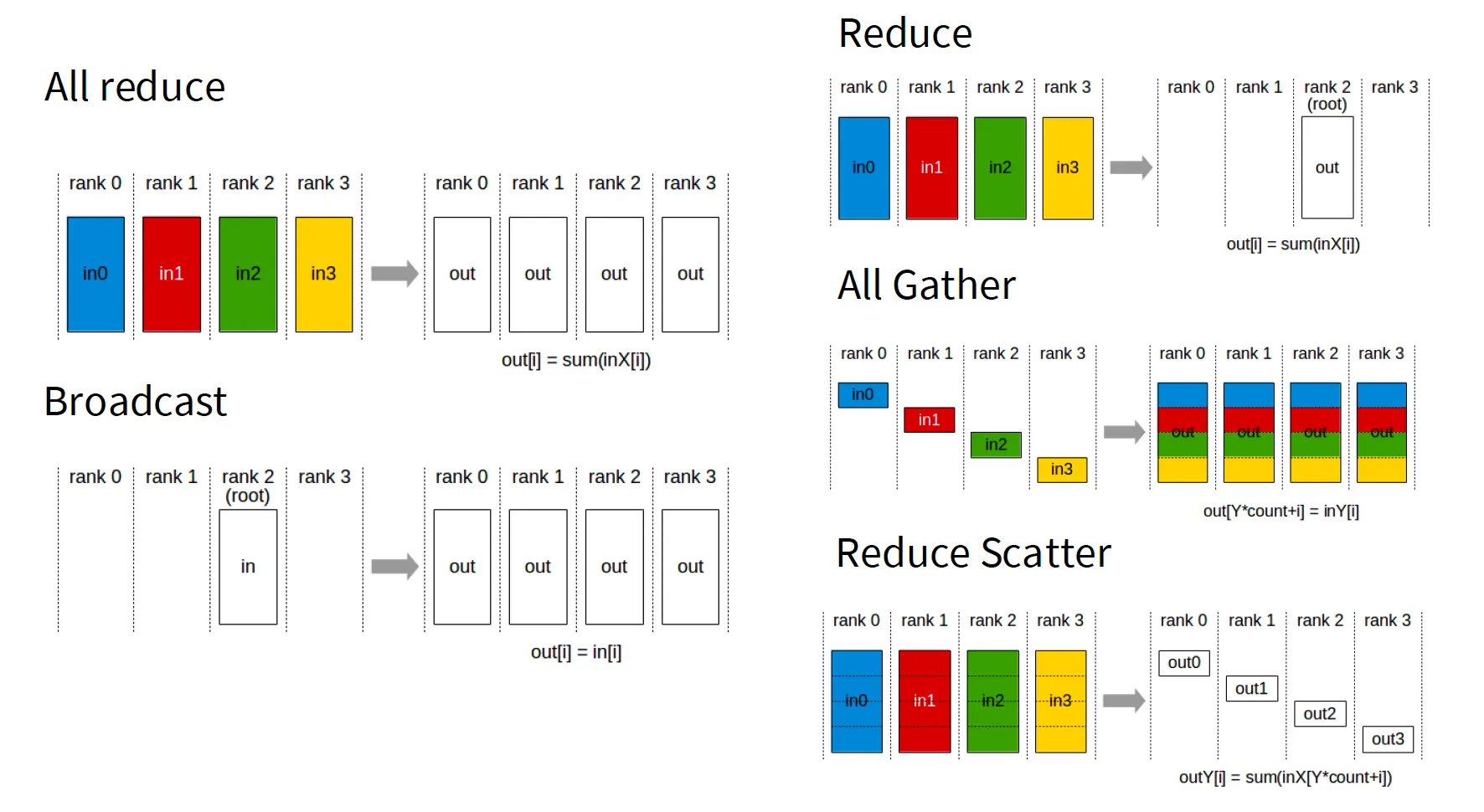
NCCL 组件的使用流程如下(图片来源: NCCL通信C++示例(一): 基础用例解读与运行):
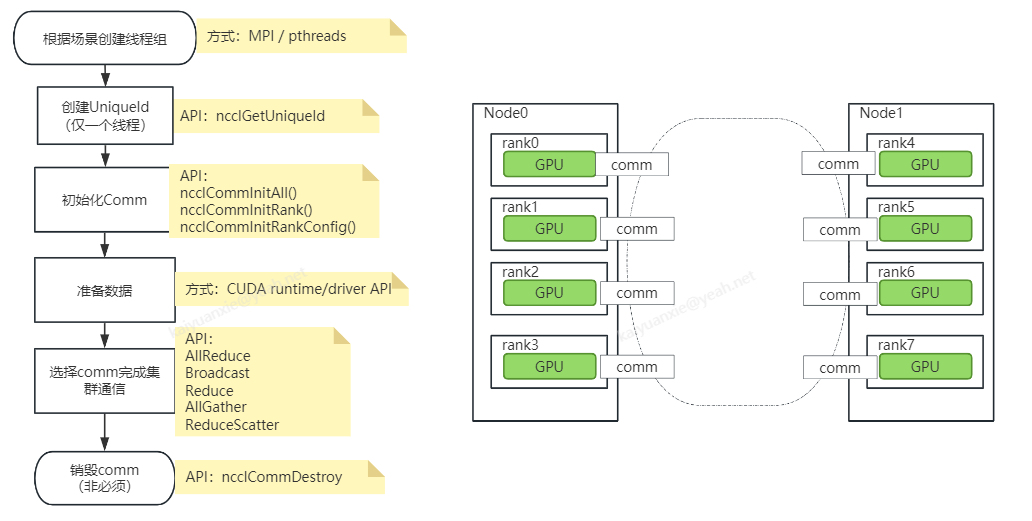
一些概念
- communicator:每个GPU参与集群通信的handle,整体 NCCL API 都基于 communicator 展开,生命周期包括创建、通信、销毁等;
- uniqueId:生成一个唯一id,用于 communicator 的初始化,基于同一个 uniqueId 初始化的多个 communicator 组成了一个通信集群;
- rank:通信集群中每个GPU的序号,比如总共8卡的集群,则 rank 分别为 0~7,这里指 global rank,多机多卡的情况下,还有 local rank,指单台机器上 GPU 的本地序号;
- node:多机多卡情况下,单台机器称为一个 node,比如上图右边就是2个node组成的8卡集群
具体到代码,可以看看集群是如何初始化的:
TinyTorch/src/Distributed/BackendNCCL.cpp
ncclUniqueId commId;
std::string key = NCCL_COMM_ID_PREFIX + std::to_string(ncclCommCounter_++);
if (getRank() == 0) {
NCCL_CALL(ncclGetUniqueId(&commId));
store_->set(key, std::string(reinterpret_cast<char*>(&commId), sizeof(commId)));
} else {
auto idData = store_->get(key);
if (idData.size() != sizeof(commId)) {
setError(BackendErrorType::COMM_ERROR);
return nullptr;
}
std::memcpy(&commId, idData.data(), sizeof(commId));
}
auto comm = NCCLComm::create(getSize(), getRank(), commId, device.index);如果是 rank 0(作为 master),通过 ncclGetUniqueId 创建一个 uniqueId,然后广播给其它设备(store_->set),然后所有设备(包括 rank 0)基于这个 uniqueId 初始化 communicator,即完成集群的初始化,communicator 的初始化通过函数 ncclCommInitRankConfig 实现,参数除了 uniqueId,还有总的 rank 数、当前设备的 rank,以及一些额外的配置(如非阻塞模式等)
TinyTorch/src/Distributed/NCCLUtils.h
static std::shared_ptr<NCCLComm> create(int numRanks, int rank, ncclUniqueId commId, DeviceIndex deviceIndex) {
cuda::CudaDeviceGuard gpuGuard(deviceIndex);
auto comm = std::make_shared<NCCLComm>();
ncclConfig_t config = NCCL_CONFIG_INITIALIZER;
config.blocking = 0; // Enable non-blocking mode
NCCL_CHECK(ncclCommInitRankConfig(&(comm->ncclComm_), numRanks, commId, rank, &config));
comm->rank_ = rank;
comm->deviceIndex_ = deviceIndex;
comm->initialized_ = false;
return comm;
}基础组件
上面提到将 uniqueId 广播给其它设备是通过 store_->set 来实现,这就涉及到我们在 NCCL 之上封装的一些组件,主要有:
- Backend:分布式通信后端,如 NCCL、Gloo、MPI,这里我们只实现了 NCCL
- ProcessGroup:进程组,封装集群通信,提供 collective API(如 allreduce、broadcast)等
- Work:集群操作接口返回的异步handle,接口包括 wait、abort、result 等
- Store:用于设备间共享元数据(如 rank、world size、初始化信息)
- TCPStore:基于 TCP socket
- FileStore:基于文件系统
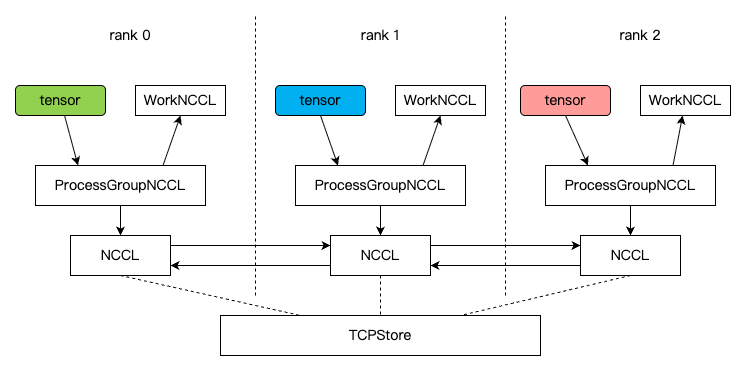
如上图,ProcessGroup 类似于 manager 的角色,对外提供集群操作接口,上层将数据(tensor)通过接口提交给 ProcessGroup,获得一个 Work 对象(后续可以异步读取结果),ProcessGroup 则把数据转交给 Backend,比如 NCCL,Store 则主要用于 Backend 的初始化,注意实际通信数据的传输是 NCCL 组件来完成,并不依赖 Store
DDP 实现
分布式训练的常用模式有如下几种:
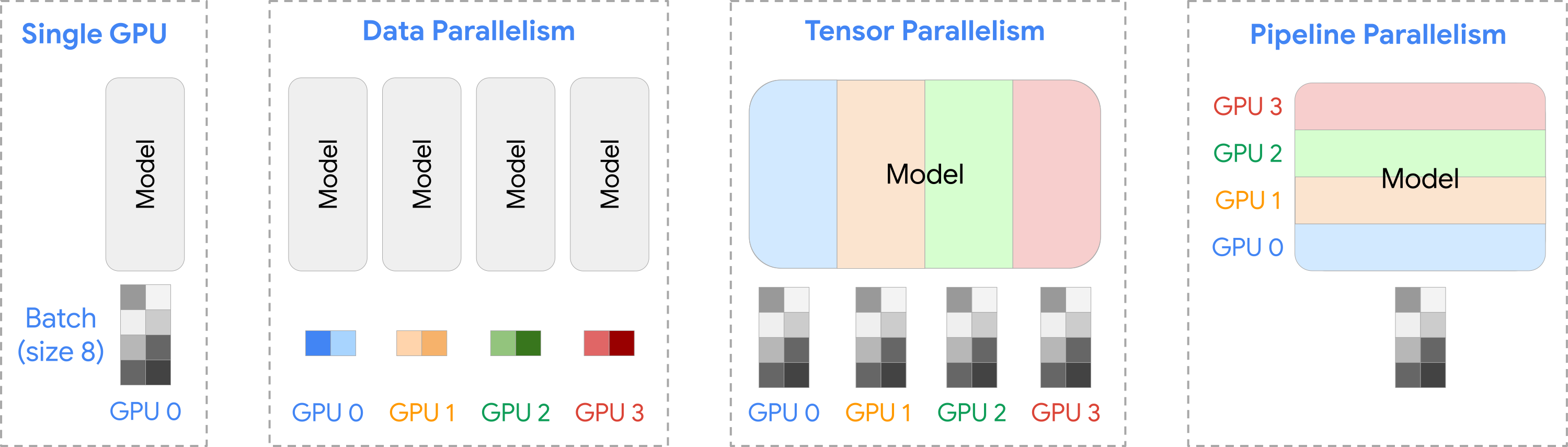
DDP 则属于 Data Paralleism,其原理如下,我们先将训练数据在多卡上进行划分,然后每张卡上跑一个 batch 后,对梯度进行 all reduce(求平均),这样就相当于实际是 N 倍 batch 来训练,达到了并行加速的效果,这里还有一些优化实现,如 all reduce 在多卡上的优化算法(如 Ring-AllReduce)、对梯度进行分桶合并后传输、计算 stream 和通信 stream overlap 等。
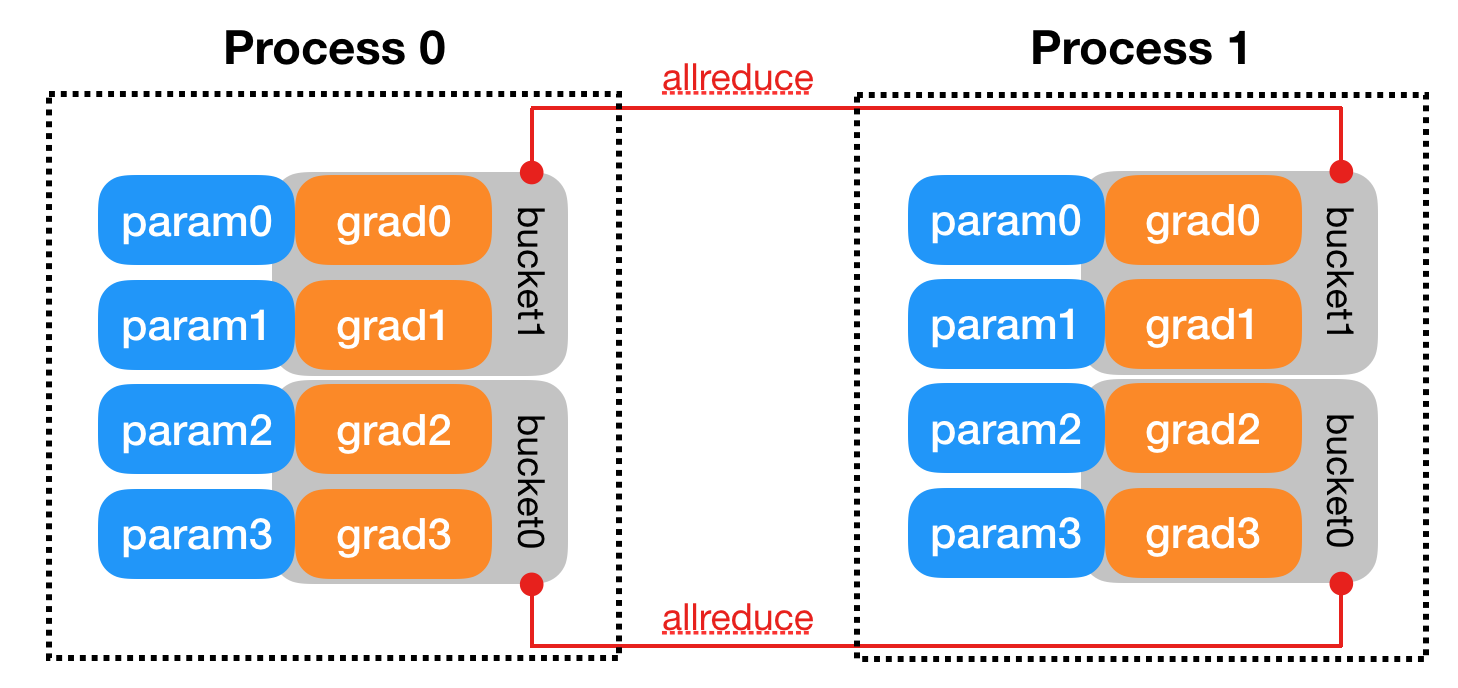
具体到实现上,主要包括 DistributedSampler 和 Reducer 两个类:
DistributedSampler 用于对训练数据的划分
TinyTorch/src/Distributed/DistributedSampler.cpp
auto offset = static_cast<int64_t>(numSamples_ * rank_);
indices_.assign(allIndices.begin() + offset, allIndices.begin() + offset + static_cast<int64_t>(numSamples_));Reducer 则主要实现对梯度的分桶和 all reduce,首先注册模型参数梯度的回调:
void Reducer::registerHooks() {
for (int64_t bIdx = 0; bIdx < static_cast<int64_t>(buckets_.size()); bIdx++) {
auto& bucket = buckets_[bIdx];
for (int64_t pIdx = 0; pIdx < static_cast<int64_t>(bucket.params.size()); pIdx++) {
auto& param = bucket.params[pIdx];
ASSERT(param != nullptr);
...
param->registerHook(¶meterHookFn, ctx.get());
...
}
}
}然后在梯度完成的回调中,将梯度 tensor 填充到 bucket 的临时 buffer,最后对 bucket 进 行 reduce
void Reducer::onGradReady(int64_t bucketIdx, int64_t paramIdx, const Tensor& grad) {
auto& bucket = buckets_[bucketIdx];
int64_t offset = bucket.paramOffsets[paramIdx];
int64_t size = bucket.paramSizes[paramIdx];
bucket.flatBuffer.narrow(0, offset, size).copy_(grad.flatten());
bucket.readyCount++;
if (bucket.readyCount == static_cast<int64_t>(bucket.params.size())) {
bucket.reduceStarted = true;
reduceBucket(bucketIdx);
}
}
void Reducer::reduceBucket(int64_t bucketIdx) {
auto& bucket = buckets_[bucketIdx];
std::vector<Tensor> tensors = {bucket.flatBuffer};
bucket.work = processGroup_->allReduce(tensors);
...这里要注意的主要是计算 stream 和通信 stream 的 overlap,即我们在 backward 的时候,参数的 grad 一旦计算出来就写入 bucket,继续剩下参数的 grad 计算,与此同时 bucket 满了就开始 NCCL 通信,使得计算和通信同时进行,从而提升系统性能。在本项目中对 stream 的管理进行了简化,每个 device 只创建一个计算 stream 和一个通信 stream,stream 之间通过 event 进行同步,具体可查看 BackendNCCL::getNCCLStream 和 WorkNCCL::wait 的实现。
多卡实测
这里我们还是以 MNIST 训练为例,使用 2×2 总计4卡 A10 来进行 DDP 训练,大约 2s 完成一个 epoch,而如果单卡 A10 目前需要 5s 左右,当然目前的 DDP 实现主要还是功能完成为主,还需要进一步的性能优化
[DEBUG] demo_ddp ...
[DEBUG] deviceCount: 2
[DEBUG] Init ProcessGroup: method=tcp, rank=0, world_size=4, master=9.165.6.73:29500, isServer=true, waitWorkers=true
[INFO] TCPStore: Worker registered. Current workers: 1/4
[INFO] TCPStore: Worker registered. Current workers: 2/4
[INFO] TCPStore: Worker registered. Current workers: 3/4
[INFO] TCPStore: Worker registered. Current workers: 4/4
[INFO] TCPStore: All 4 workers registered successfully
[DEBUG] Init ProcessGroup success, backend=nccl
[DEBUG] Train with device: cuda:0
[DEBUG] Train Epoch: 1 [0/60000 (0%)] Loss: 2.306863, Elapsed: 0.15s
[DEBUG] Train Epoch: 1 [2560/60000 (4%)] Loss: 1.983107, Elapsed: 0.21s
...
...
[DEBUG] Train Epoch: 1 [58880/60000 (98%)] Loss: 0.100589, Elapsed: 1.86s
[DEBUG] Test set: Average loss: 0.1380, Accuracy: 9560/10000 (96%), Elapsed: 0.17s
[DEBUG] Time cost: 2181 ms完整测试代码: TinyTorch/demo/demo_ddp.cpp